Recently I spoke at the Pipeline Conference in London. I gave a talk on “Optimising Continuous Delivery” to a bunch of people who were self-selected as interested in Continuous Delivery, most of them would already consider themselves CD practitioners, Pipeline is a conference dedicated to learning about CD!
Early in my talk I described some of the ground-rules for CD, those practices that I consider “table-stakes” for playing. One of my slides is intentionally slightly jokey. It describes my advice for branching strategies in the context of CD.

I knew that this would be contentious, it is always contentious. This is the practice that I advise that I get most push-back on. EVERY TIME!
Before I had got home from the conference my twitter account ‘@davefarley77’ had gone a bit mad. Lots and lots of posts, for and against, questions and challenges and while a week later it has slowed down a bit, the rumblings continue.
I wrote about feature branching some years ago. I was about to say that the debate has moved on, but in reality I don’t think that it has. The same questions and issues arise. So this blog post is meant to add a few more thoughts on the topic.
The push-back that I get when I express my view that any form of branching is counter, in principle, to the ideas of Continuous Integration is varied.
At one extreme I get “Heretic, burn him at the stake” kind of feedback, at the other “Yes, but it can’t possibly work without Feature Branching – you must work in small teams and/or on trivially simple projects”.
The first point is fair enough, I am, constitutionally, a heretic. I like to be skeptical about “received wisdom” and question it.
In this case though, my views on branching are from experience rather than mere academic skepticism. I have been a professional software developer for nearly four decades now. I have tried most things over the years. I have refined my understanding of what works and what doesn’t on a lot of projects, trying a lot of different tools, technologies, methodologies and techniques.
In response to the second class of “push-back” I do sometimes work in small teams, but also with some of the biggest companies in the world. For the past three decades I think that it is fair to categorise most of my development work as at the more complex end of the scale. Which is one of the reasons that I take some of these disciplines quite so seriously.
I am an adherent of agile principles and take them to their extreme with my flavour of Continuous Delivery when I am in a position to decide, or influence the decision.
I first practiced a version of Continuous Integration in 1991. We had a continual rolling build, a home built version control system, written in shell-script, and even a few simple “unit tests” on our C++ project. This pre-dated the popularity of CI by a considerable margin, but it worked really well!
What I learned on this project, and on many others, small and MASSIVE, is that what really matters is feedback! Fast and high-quality. The longer that you defer feedback, the greater the risk that something unexpected, and usually bad, will happen.
This is one of the ideas that inspired the evolution from Continuous Integration to Continuous Delivery. We wanted better feedback, greater insight, into the effect of our changes, whatever their nature.
So you can tell, I am a believer in, and advocate for, Continuous Integration. We create better code when we get fast feedback on our changes all of the time.
CI is a publication based approach to development. It allows me to publish my ideas to the rest of my team and see the impact of them on others. It also alows the rest of my team to see, as it is evolving, the direction of my thinking. When teams practice CI what they get is the opportunity to “Fail Fast”. If something is a problem, they will spot it REALLY quickly, usually within a handful of minutes.
CI works best when publications/commits are frequent. We CI practitioners actively encourage commits multiple times per day. When I am working well, I am usually committing every 15 minutes or so. I practice TDD and so “Red-Green-Refactor-Commit” is my mantra.
This frequency doesn’t change with the complexity of the code or size of the team. It may change with how clearly I am thinking about the problem or with the maturity of the team and their level of commitment to CI.
What I mean by that, is that once bitten by the feedback bug, you will work VERY hard to feed your habit. If your build is too slow, work to speed it up. If your tests are too slow, write better tests. If your hardware is too slow on your build machines, buy bigger boxes! I have worked on teams on some very large codebases, with complex technologies that still managed to get the fast feedback that we needed to do high-quality work!
If you care enough, if you think this important enough, you can get feedback fast enough, whatever your scale! It is not always easy, but it has always been possible in every case that I have seen so far – including some difficult, challenging tech and some VERY large builds and test suites!
“What has all of this got to do with branching?” I hear you ask. Well if CI is about exposing our changes as frequently as possible, so that we can get great feedback on our ideas, branching, any form of branching, is about isolating change. A branch is, by-design, intended to hide change in one part of the code from other developers. It is antithetical to CI, the clue is in the name “CONTINUOUS INTEGRATION”!
To some degree this isolation may not matter too much. If you branch, but your branch is VERY short-lived, you may be able to get the benefits of CI. There are a couple of problems with this though. First, that this is not what most teams do. Most teams don’t merge their branch until the “feature” that they are working on is complete. This is called “Feature Branching”.
Feature Branching is very nice from the perspective of an individual developer, but sub-optimal from the perspective of a team. We would all like to be able to ignore what everyone else is doing and get on with our work. Unfortunately code isn’t like that. Even in very well factored code-bases with beautiful separation-of-concerns and wonderfully loosely-coupled components, some changes affect other parts of the system.
I am not naive enough to assert that Feature Branching can never work, you can make anything work if you try hard and are lucky. Even waterfall projects occasionally produced some software! My assertion is that feature branching is higher-risk and, at the limit, a less efficient approach.
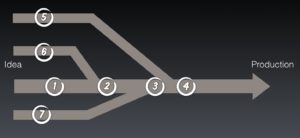
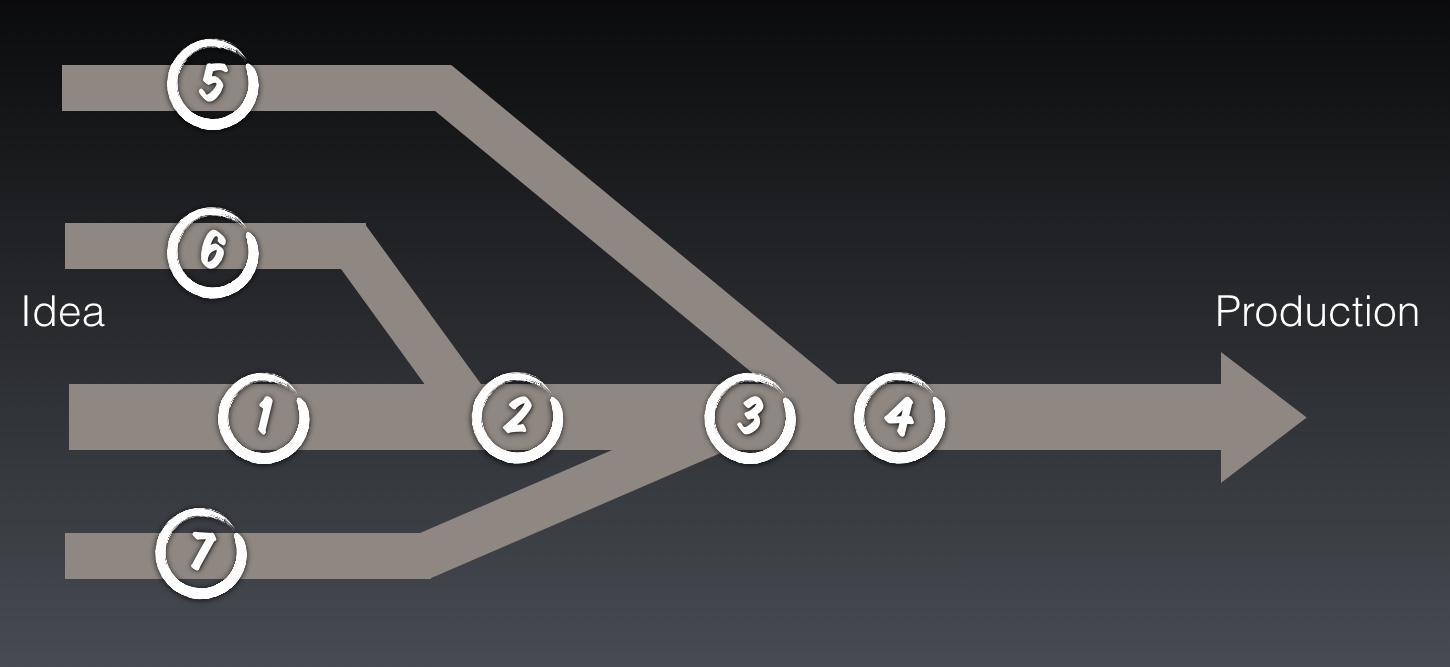
The diagram above shows several paths from idea to working software in production. So if we want effective, high-quality feedback where in this diagram should we evaluate our changes? Point 1 is clearly no good, the changes on the branches, 5, 6 and 7, are never evaluated.
We could evaluate the changes after every merge to trunk, 2, 3 and 4. This is what lots of Feature branching teams do. The problem now is twofold:
1) We get no feedback on the quality of our work until we think that we are finished – Too Late!
2) We have zero visibility of what is happening on other branches and so our work may not merge. – Too Risky!
Before the HP Laserjet Firmware team made their move to Continuous Delivery, their global development team spent 5 times as much effort on merging changes between branches as on developing new features!
(See from time 47:16 in this presentation also “A Practical Approach To Large Scale Agile Development”)
At this point my branch-obsessed interlocutors say “Yes, but merging is nearly free with modern tools”.
It is true! Modern distributed Version Control Systems, like GIT, have very good merge tools. They can only go so far though. Modern merge tools are good at the optimistic lock strategy of deferring locking things down until you see a conflict, at which point they request some help, your help. Most of the time merges are simple and automatic, but often enough, they are not.
As soon as you need to intervene in a merge there is a cost and until the point of merging you don’t know how big that cost will be. Ever got to merge some change that you have worked on for several days or a week, only to find that the differences are so great that you can’t merge? Lots of teams do find themselves in this position from time to time.
Back to our diagram. What feature branch teams sometimes do is run a dual CI system, they run CI on the branches AND after the merge to Trunk. This is certainly safer, but it is also slow.
As ever, the definitive point is the testing that happens at the point of merge to Trunk. It is only at this point that you can honestly say “Yes, my change works with everyone else’s.”. Before that, you are hoping that someone else hasn’t done something horrid on another branch that breaks your stuff when you merge.
This approach is safer because you are getting some feedback sooner, from the CI running on your feature branch, but this branch is telling lies. It is not the real story. This is not a change set that will ever make it into production, it isn’t integrated with other branches yet. So even if all your tests pass on this branch, some may fail when you merge. It is slow because you are now building and running everything at least twice for a given commit.
The real, authoritative feedback happens when you evaluate the set of changes, post merge, that will be deployed into production, until your branch is finished and merged onto Trunk, everything else is a guess.
CI advocates advise working on Trunk all the time. If you want to be pedantic, then yes, your local copy of the code is a form of branch, but what we mean by “all the time” is that we are going to make changes in tiny steps. Each change is itself atomic and leaves the code in a working state, meaning that the code continues to work and deliver value. We will usually commit many of these atomic changes every day. This often means that we are happy to deploy changes into production that are not yet complete, but don’t break anything!
CI, like every other engineering practice, comes with some compromises. It means that we are only allowed to commit changes that keep the system working. We NEVER intentionally commit a change that we know doesn’t work. If we do break something the build stops and rejects our change, that is the heart of CI.
This means that we have to grow our features over multiple commits, if we want regular, fast, authoritative feedback. This, in turn, changes the way that we go about designing our features. It feels more like we “grow” them through a sequence of commits rather than take them aside, design them and build them in isolation and then merge them.
This is a pretty big difference. I think that this is one of the reasons for the second category of push-backs that I tend to get from people who are more used to using branches.
Q: “Yes, but how do you make anything complex in 15 minutes?”
A: You don’t, you break complex things into a series of small, simple changes.
Q: “But how can a team fix bugs in production?”
A: They feed the fixes in to the stream of commits, like any other change to the system.
Q: “Ah yes, but how do you do code reviews?”
A: Pair Programming is my preferred approach. You get better code reviews and much more.
Q: “Ah, but you can’t do this for software like XXX or using technology like YYY”
A: I have build systems-software, messaging systems, clustering systems, large volume data-base backed systems, whole enterprise systems, some of the highest performing trading software in the world, as well as web-sites, games and pretty much any other type of software that you can think of using this approach.
I have done it in Java, C#, C++, Python, Ruby, Javascript, shell-script, FPGA systems, Embedded software and COBOL. I have seen other teams using this approach on an even wider variety of technologies and products. I think it works!
CI is about speed and clarity of feedback. We want a definitive picture of the quality of our work, which means that we must evaluate, precisely, the code that will go into production. Anything else is guessing. We want our feedback fast and so we will optimise for that. We work to position the machinery that provides that feedback so that it can try our changes destined for production as soon as possible, that is, as close to the point that we made the changes as we can achieve.
Finding our that my code is stupid or broken within 2 minutes of typing it is very different to having to wait, even as short-a-time as an hour for that insight. It changes the way that I work. I can proceed faster, with more confidence and, when I do mess-up, I can step back with very little cost.
So we want definitive feedback fast. That means that anything that hides change gets in the way and slows us down. Any form of branching is antithetical to Continuous Integration.
If your branch lasts less than a day, my argument against it is weakened, but in that case I will pose the question “why bother with branches?”.
I work on Trunk, “master” in my GIT repos. I commit to master locally and push immediately, when I am networked, to my central master repo where CI runs. That’s it!
I do compromise the way that I work to achieve this. I use branch by abstraction, dark-releasing and sometimes feature-flags. What I get in return is fast, definitive (at least to the quality of my testing) feedback.
Last years “State of DevOps Report” claimed that my style of development is a defining characteristic of “High Performing Teams”. If you are not merging your changes to Trunk at least daily, it predicts that your outcomes are more closely aligned with “Lower Performing Teams”.
There is a lot more to this, CI is not a naive approach it is well-thought out and very widely practiced in some of the most successful companies in the world. Trunk-based development is a core practice to CI and CD, it really is very difficult to achieve all of the benefits of CI or CD in the absence of Trunk-based development. You can read more about these ideas on the excellent Trunk-Based-Development site.