
Recently I spoke at the Pipeline Conference in London. I gave a talk on “Optimising Continuous Delivery” to a bunch of people who were self-selected as interested in Continuous Delivery, most of them would already consider themselves CD practitioners, Pipeline is a conference dedicated to learning about CD!
Early in my talk I described some of the ground-rules for CD, those practices that I consider “table-stakes” for playing. One of my slides is intentionally slightly jokey. It describes my advice for branching strategies in the context of CD.

I knew that this would be contentious, it is always contentious. This is the practice that I advise that I get most push-back on. EVERY TIME!
Before I had got home from the conference my twitter account ‘@davefarley77’ had gone a bit mad. Lots and lots of posts, for and against, questions and challenges and while a week later it has slowed down a bit, the rumblings continue.
I wrote about feature branching some years ago. I was about to say that the debate has moved on, but in reality I don’t think that it has. The same questions and issues arise. So this blog post is meant to add a few more thoughts on the topic.
The push-back that I get when I express my view that any form of branching is counter, in principle, to the ideas of Continuous Integration is varied.
At one extreme I get “Heretic, burn him at the stake” kind of feedback, at the other “Yes, but it can’t possibly work without Feature Branching – you must work in small teams and/or on trivially simple projects”.
The first point is fair enough, I am, constitutionally, a heretic. I like to be skeptical about “received wisdom” and question it.
In this case though, my views on branching are from experience rather than mere academic skepticism. I have been a professional software developer for nearly four decades now. I have tried most things over the years. I have refined my understanding of what works and what doesn’t on a lot of projects, trying a lot of different tools, technologies, methodologies and techniques.
In response to the second class of “push-back” I do sometimes work in small teams, but also with some of the biggest companies in the world. For the past three decades I think that it is fair to categorise most of my development work as at the more complex end of the scale. Which is one of the reasons that I take some of these disciplines quite so seriously.
I am an adherent of agile principles and take them to their extreme with my flavour of Continuous Delivery when I am in a position to decide, or influence the decision.
I first practiced a version of Continuous Integration in 1991. We had a continual rolling build, a home built version control system, written in shell-script, and even a few simple “unit tests” on our C++ project. This pre-dated the popularity of CI by a considerable margin, but it worked really well!
What I learned on this project, and on many others, small and MASSIVE, is that what really matters is feedback! Fast and high-quality. The longer that you defer feedback, the greater the risk that something unexpected, and usually bad, will happen.
This is one of the ideas that inspired the evolution from Continuous Integration to Continuous Delivery. We wanted better feedback, greater insight, into the effect of our changes, whatever their nature.
So you can tell, I am a believer in, and advocate for, Continuous Integration. We create better code when we get fast feedback on our changes all of the time.
CI is a publication based approach to development. It allows me to publish my ideas to the rest of my team and see the impact of them on others. It also alows the rest of my team to see, as it is evolving, the direction of my thinking. When teams practice CI what they get is the opportunity to “Fail Fast”. If something is a problem, they will spot it REALLY quickly, usually within a handful of minutes.
CI works best when publications/commits are frequent. We CI practitioners actively encourage commits multiple times per day. When I am working well, I am usually committing every 15 minutes or so. I practice TDD and so “Red-Green-Refactor-Commit” is my mantra.
This frequency doesn’t change with the complexity of the code or size of the team. It may change with how clearly I am thinking about the problem or with the maturity of the team and their level of commitment to CI.
What I mean by that, is that once bitten by the feedback bug, you will work VERY hard to feed your habit. If your build is too slow, work to speed it up. If your tests are too slow, write better tests. If your hardware is too slow on your build machines, buy bigger boxes! I have worked on teams on some very large codebases, with complex technologies that still managed to get the fast feedback that we needed to do high-quality work!
If you care enough, if you think this important enough, you can get feedback fast enough, whatever your scale! It is not always easy, but it has always been possible in every case that I have seen so far – including some difficult, challenging tech and some VERY large builds and test suites!
“What has all of this got to do with branching?” I hear you ask. Well if CI is about exposing our changes as frequently as possible, so that we can get great feedback on our ideas, branching, any form of branching, is about isolating change. A branch is, by-design, intended to hide change in one part of the code from other developers. It is antithetical to CI, the clue is in the name “CONTINUOUS INTEGRATION”!
To some degree this isolation may not matter too much. If you branch, but your branch is VERY short-lived, you may be able to get the benefits of CI. There are a couple of problems with this though. First, that this is not what most teams do. Most teams don’t merge their branch until the “feature” that they are working on is complete. This is called “Feature Branching”.
Feature Branching is very nice from the perspective of an individual developer, but sub-optimal from the perspective of a team. We would all like to be able to ignore what everyone else is doing and get on with our work. Unfortunately code isn’t like that. Even in very well factored code-bases with beautiful separation-of-concerns and wonderfully loosely-coupled components, some changes affect other parts of the system.
I am not naive enough to assert that Feature Branching can never work, you can make anything work if you try hard and are lucky. Even waterfall projects occasionally produced some software! My assertion is that feature branching is higher-risk and, at the limit, a less efficient approach.
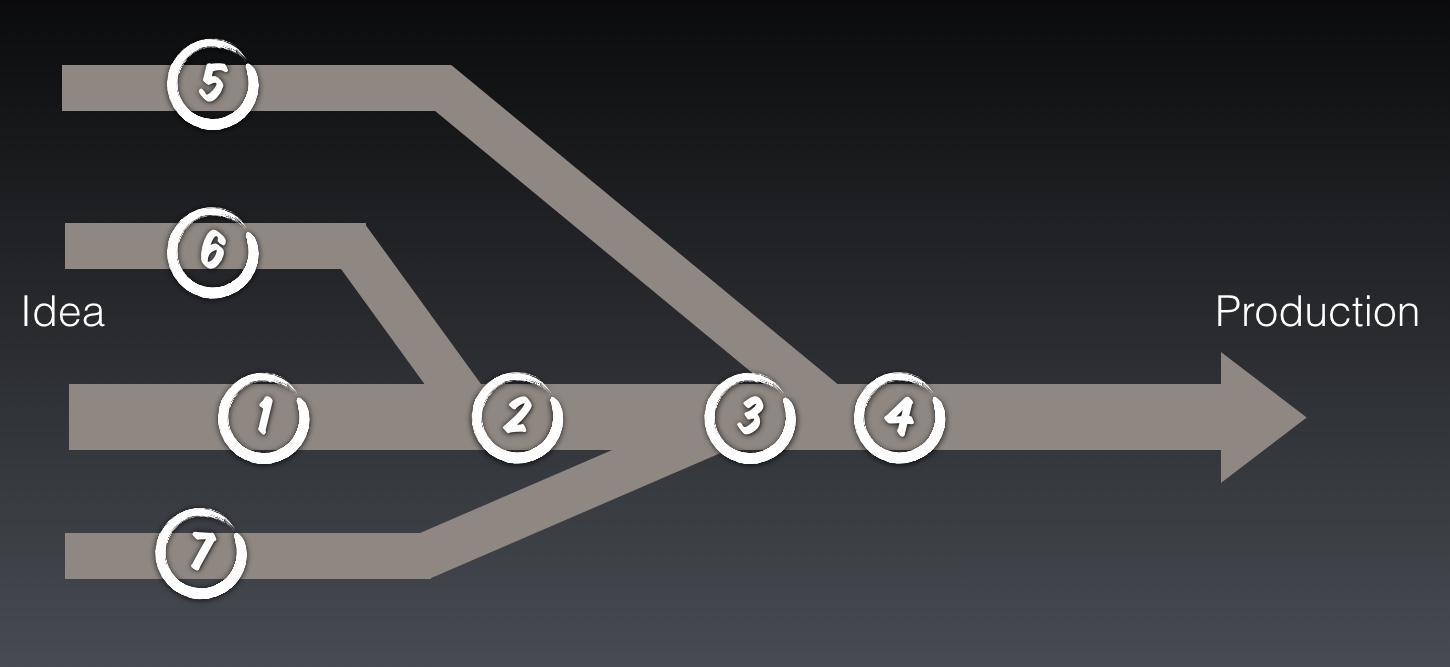
The diagram above shows several paths from idea to working software in production. So if we want effective, high-quality feedback where in this diagram should we evaluate our changes? Point 1 is clearly no good, the changes on the branches, 5, 6 and 7, are never evaluated.
We could evaluate the changes after every merge to trunk, 2, 3 and 4. This is what lots of Feature branching teams do. The problem now is twofold:
1) We get no feedback on the quality of our work until we think that we are finished – Too Late!
2) We have zero visibility of what is happening on other branches and so our work may not merge. – Too Risky!
Before the HP Laserjet Firmware team made their move to Continuous Delivery, their global development team spent 5 times as much effort on merging changes between branches as on developing new features!
(See from time 47:16 in this presentation also “A Practical Approach To Large Scale Agile Development”)
At this point my branch-obsessed interlocutors say “Yes, but merging is nearly free with modern tools”.
It is true! Modern distributed Version Control Systems, like GIT, have very good merge tools. They can only go so far though. Modern merge tools are good at the optimistic lock strategy of deferring locking things down until you see a conflict, at which point they request some help, your help. Most of the time merges are simple and automatic, but often enough, they are not.
As soon as you need to intervene in a merge there is a cost and until the point of merging you don’t know how big that cost will be. Ever got to merge some change that you have worked on for several days or a week, only to find that the differences are so great that you can’t merge? Lots of teams do find themselves in this position from time to time.
Back to our diagram. What feature branch teams sometimes do is run a dual CI system, they run CI on the branches AND after the merge to Trunk. This is certainly safer, but it is also slow.
As ever, the definitive point is the testing that happens at the point of merge to Trunk. It is only at this point that you can honestly say “Yes, my change works with everyone else’s.”. Before that, you are hoping that someone else hasn’t done something horrid on another branch that breaks your stuff when you merge.
This approach is safer because you are getting some feedback sooner, from the CI running on your feature branch, but this branch is telling lies. It is not the real story. This is not a change set that will ever make it into production, it isn’t integrated with other branches yet. So even if all your tests pass on this branch, some may fail when you merge. It is slow because you are now building and running everything at least twice for a given commit.
The real, authoritative feedback happens when you evaluate the set of changes, post merge, that will be deployed into production, until your branch is finished and merged onto Trunk, everything else is a guess.
CI advocates advise working on Trunk all the time. If you want to be pedantic, then yes, your local copy of the code is a form of branch, but what we mean by “all the time” is that we are going to make changes in tiny steps. Each change is itself atomic and leaves the code in a working state, meaning that the code continues to work and deliver value. We will usually commit many of these atomic changes every day. This often means that we are happy to deploy changes into production that are not yet complete, but don’t break anything!
CI, like every other engineering practice, comes with some compromises. It means that we are only allowed to commit changes that keep the system working. We NEVER intentionally commit a change that we know doesn’t work. If we do break something the build stops and rejects our change, that is the heart of CI.
This means that we have to grow our features over multiple commits, if we want regular, fast, authoritative feedback. This, in turn, changes the way that we go about designing our features. It feels more like we “grow” them through a sequence of commits rather than take them aside, design them and build them in isolation and then merge them.
This is a pretty big difference. I think that this is one of the reasons for the second category of push-backs that I tend to get from people who are more used to using branches.
Q: “Yes, but how do you make anything complex in 15 minutes?”
A: You don’t, you break complex things into a series of small, simple changes.
Q: “But how can a team fix bugs in production?”
A: They feed the fixes in to the stream of commits, like any other change to the system.
Q: “Ah yes, but how do you do code reviews?”
A: Pair Programming is my preferred approach. You get better code reviews and much more.
Q: “Ah, but you can’t do this for software like XXX or using technology like YYY”
A: I have build systems-software, messaging systems, clustering systems, large volume data-base backed systems, whole enterprise systems, some of the highest performing trading software in the world, as well as web-sites, games and pretty much any other type of software that you can think of using this approach.
I have done it in Java, C#, C++, Python, Ruby, Javascript, shell-script, FPGA systems, Embedded software and COBOL. I have seen other teams using this approach on an even wider variety of technologies and products. I think it works!
CI is about speed and clarity of feedback. We want a definitive picture of the quality of our work, which means that we must evaluate, precisely, the code that will go into production. Anything else is guessing. We want our feedback fast and so we will optimise for that. We work to position the machinery that provides that feedback so that it can try our changes destined for production as soon as possible, that is, as close to the point that we made the changes as we can achieve.
Finding our that my code is stupid or broken within 2 minutes of typing it is very different to having to wait, even as short-a-time as an hour for that insight. It changes the way that I work. I can proceed faster, with more confidence and, when I do mess-up, I can step back with very little cost.
So we want definitive feedback fast. That means that anything that hides change gets in the way and slows us down. Any form of branching is antithetical to Continuous Integration.
If your branch lasts less than a day, my argument against it is weakened, but in that case I will pose the question “why bother with branches?”.
I work on Trunk, “master” in my GIT repos. I commit to master locally and push immediately, when I am networked, to my central master repo where CI runs. That’s it!
I do compromise the way that I work to achieve this. I use branch by abstraction, dark-releasing and sometimes feature-flags. What I get in return is fast, definitive (at least to the quality of my testing) feedback.
Last years “State of DevOps Report” claimed that my style of development is a defining characteristic of “High Performing Teams”. If you are not merging your changes to Trunk at least daily, it predicts that your outcomes are more closely aligned with “Lower Performing Teams”.
There is a lot more to this, CI is not a naive approach it is well-thought out and very widely practiced in some of the most successful companies in the world. Trunk-based development is a core practice to CI and CD, it really is very difficult to achieve all of the benefits of CI or CD in the absence of Trunk-based development. You can read more about these ideas on the excellent Trunk-Based-Development site.
I’d love to hear some war stories that led you to a strong conclusion that pair-programming and no branches is easier to establish than a practice of having short-lived (as in, up to a few hours long) feature branches and pull requests backed by fast builds.
Through personally being in touch with hundreds of companies using Semaphore CI, I don’t recall seeing a team that doesn’t do feature branches. Both approaches can work and you’ll fail in both if you don’t understand the challenges and pitfalls. In that sense it’s really valuable to document ways to fail, like you are doing. Not to mention how it depends on the archicture and tech stack… 🙂
I don’t think that I said “easier to establish” 😉
The techniques that I recommend are hard to adapt to, but they are, IMO, better!
So NOT “easier to establish” but “more effective”.
I agree that the techniques that I am recommending are less common than a, to my mind, slightly broken mis-interpretation of CI – which is the commonest approach. The point is not “how popular” but rather “how effective”. The teams that I have seen doing this produce higher-quality code more quickly than the teams that I have seen practicing the common approach. Which is really why I wrote this piece in the first place. 🙂
Hi Marko! Seems like you are equating feature-branches with so called task/topic branches. They are different things. Task/topic branches are for a single small development change. Feature branches are by definition for things that are bigger than a story or task, and might even barely fit into a sprint (if at all).
Features (and feature-branches) span multiple stories and tasks, and if developed (and integrated) on a branch prior to merging to main-trunk, then unless the work on the feature branch is broken down into smaller stories/tasks and integrated to main-trunk just as frequently as if they hadnt been done on a feature-branch first, then there is delayed integration & feedback.
If you are doing short-lived branches that live for a few hours (or even less than a day), then those are development tasks (or at most a small story) per branch, and is more accurately called a task-branch, or (occasionally) story-branch, or more generally a “topic” branch (where the “topic” is referring to a leaf-level story or task, and is not something that is bigger than a user-story).
Thanks Dave for bringing this issue back to the foreground again (as it seems much needed). I think there are some bigger issues at play as to why too many folks still don’t seem to “get” what the issue is (and is not) with branching and merging, whether it is done within the codebase using version-control, or in the code-structure itself (with toggles).
Unfortunately, this leads to a lot of misinformation (on both sides), or even stuff that makes sense, to those who possess the proper mindset/perspective, but not to the rest.
This is also problem with a lot of the arguments that talk about the perils of long-lived branches (as well as “feature” branches). The issue is not the length/duration of the branch, it is the frequency of the feedback and synchronization (from merge-integration). You can say that until youre blue in the face, but if you start-off with the argument with the wrong or controversial thing, youve all to often lost your audiences’ focus on what you most need them to hear and understand.
There are some fundamentally different ways (mindsets) of thinking about (and hence understanding) branching and branches. As someone who wrote extensively about this topic early on (the “Streamed Lines” branching patterns in ’98), I have more personal experience with those failures than most. We tried to focus on the context, and identify the different styles/mindsets and tradeoffs (rather than take a strongly opinionated approach for one over the other), all seemingly for naught.
To make matters worse, the so called “feature branch” was never even a pattern or recommendation back then (thru the 90s). It was more something that almost exclusively appeared in the context of very large codebases spanning multiple teams, and only for “feature teams” (the pre-agile flavor of feature-teams). Some notion of an integration codeline per-team made sense (whether it was a feature-branch, or some other kind of branch), and probably even necessary when you would otherwise have scores of developers trying to commit to the same repository during the same 60min time-period, back when “full/clean” build-times took hours rather than minutes, and commits weren’t really atomic.
How that practice migrated to small teams and small codebases still seems to defy all reason, and yet that’s exactly what happened with the likes of GitFlow and its predecessors+successors (and it most definitely does no good to “blame” vendors/products like Rational/ClearCase, or make absolute/universal statements like “never” or “always” that neglect purpose & context)
Instead, I think we need to get back to basics on the how & why of branching — what problem(s) was it designed to legitimately solve, *when* (and how) is the right way to do it, and what are the guiding principles (like the SOLID principles).
I think we have better vocabulary and understanding now than we did in the 90s and 2000s (now that Agile & DevOps & Lean are accepted and pervasive, even when culture & mindset is still lagging behind).
More on that later…
[Follow up to my previous comment]
Back to the purpose of branching and the problem(s) it was designed to solve. This one is pretty easy/basic, yet often forgotten, especially in these days of SaaS. SCM tools/systems were designed to address three “classic” SCM problems: shared data/content, concurrent editing/changes, multiple maintenance.
The problem of having shared data/content is why we should use a version-control repository in the first place (instead of filesystems and copying/backup). Concurrent editing was mostly addressed by the notion of a “checkout” using an optimistic or pessimistic licking mechanism (e.g., copy-modify-merge, or lock-modify-unlock), at the “right” granularity (single file, folder, (sub)module, or whole-repo).
The notion of branching was designed for solving the multiple maintenance problem, which is when you have multiple active versions (i.e. releases) of a codebase that “must” be supported, concurrently, during the same time. This was far more exceedingly common *before* the popularity of SaaS, when “release” and “deploy” where not only far apart in time and (physical) space but also in terms of ownership (different companies and sites).
If I had only one released version to support in the field, and the only other “version” was the one being actively developed, I might not even need branching at all (or at best only short-lived, until the next release-date). But if I had multiple different releases in the field that needed to be supported, even while working on the next latest/greatest one – then this is what branching was designed for: representing an independently active evolutionary path of development (as long as it was a *necessary* path – one that provided more value than the additional costs of supporting the previous versions).
That’s pretty much it in a nutshell. That was the correct/intended purpose and need for branching. The problem is it became popular as a strategy for parallelizing development work (prior to its deployment+release) without *proper* understanding of those costs. This is the world that viewed development as projects over products, and branches were the version-control equivalent of a nail for the project-oriented hammer.
The frequency and granularity of branching use quickly got out of hand (a “branch for every purpose” and a “purpose for every branch”, and nesting and increasingly more levels of integration-indirection), and employers and managers didn’t have the right mindset and thinking tools to understand why (tools like lean-flow, lean-startup, cost of multi-tasking, context-switching, #noprojects, relative-estimation and beyond-budgeting [#noestimates] and cost-of-delay).
Something similar has been happening with feature-toggles too (to often mis-used by being too long-lived, to frequent/fine-grained, not subject to refactoring and “clean coding”, etc.). Feature-toggling is a different form of branching (code-branching) at a different “binding-time”.
All too often, the question of branching vs toggling comes up when it probably shouldnt. When the answer is presumed to be one or the other, but is probably neither. Just focus on integrating very frequently, in small (micro-sized) chunks/tasks. The pressure to branch or toggle may be coming from a different mindset with misconceived notions about traceability vs transparency, isolation vs encapsulation, safety/stability vs liveness/speed, etc.) and should probably be solved a different way that requires neither a feature-branch nor a feature-toggle.
Shakespeare’s Polonius (from Hamlet) famously says: “Neither a borrower nor a lender be; / For loan oft loses both itself and friend.” This is well suited to branching and toggling as forms of “debt” that can compromise the fast friendship we need to maintain with fast+frequent flow and feedback.
Brad, great reply and I agree. I do wonder how you see the rise of mobile apps impacting this approach? With mobile apps it’s possible to have different versions in the field necessitating different versions in the SaaS.
why not do CI and feature branches? we just clone our build definition, and point the build at the feature branch.
I think I make it clear in the article that I think that Feature Branches slow you down. That is why I prefer not to work this way.
When doing CI *and* feature branches, the feature branch adds another level of indirection between the development change/task and the CI branch (main-trunk) which causes a delay integration & feedback unless you integrate from feature-branch to main-trunk on a per change/task basis (almost per commit).
You have to ask yourself what is the additional (intermediate) branch doing for you. If it is adding “stability” (so that main-trunk has less rapid change-volatility) then that can be valid (in the case of large codebases with multiple teams) but its still delaying CI integration frequency.
If the feature branch isnt really adding stability, then why is the additional isolation necessary? If its just to use the feature branch as a “container” for all the commits that happened for the feature, then is a branch the right way to do that if you dont need the additional isolation (and merging/integration effort) that the branch introduces?
Because CI requires a commit to mainline every 24 hours by definition. You can build your feature branch until you turn blue, but you are not integrating that code with everyone else’s. You are Continuous when you commit every 24 hours.. you integrate when you commit to trunk.
Continuous = Commit every 24 hours
Integration = Commit to TRUNK
I totally agree with ‘fast feedback’. The definitive speed of any software development is determined by the quality and speed of the feedback (and by quality, the closer to the real production feedback, the better). That’s what really good developers are good at. Feedback.
Therefore I agree that you should merge/commit often. I don’t care what we define a branch, as long as we commit often.
I do though think that most have CI wrong on another level. Most implementations of CI is wrong. If the build breaks, other developers shouldn’t be hindered. Your code should automatically be stopped from being merging/committing/pushed to the repo, if it doesn’t work.
I’ve seem much of what you describe, but also where branches was used
How do you manage CI with all development on master without hindering other users? Automatic backouts?
There are several books on this topic. The quick answer though is that you work in a series of many small changes and optimise the build and the tests to be VERY efficient. I have worked in teams that shared a repo between about 450 people.
Google do a version of this with 31,000 people – it scales very well.
There are a couple of common approaches, and many variants. The two common approaches are:
Human CI.
You use a mix of tech and team discipline to keep CI working. For example, don’t commit on a broken build and commit a fix or revert you change with 10 minutes of breaking the build.
Gated Commit.
Instead of committing to a VCS, you commit to the build. The build compiles the code and runs all of the test, and only if everything works does the build merge the changes into the VCS.
Refreshing thoughts!
My previous project had feature branches that lay dormant for a week, because of delayed code reviews. Merging afterwards was hell!
code-reviews tend to cause integration delays when the size of the change being reviewed is large and/or requires multiple other reviewers to formally “signoff” (or needs to wait for a specific person or role to do the signoff — creating a resource utilization/scheduling issue that impedes flow of change and integration/feedback. If the changes are small enough, it doesnt require as many people, and if the team is agile/collaboraive enough, it doesnt have to wait for a specific approver to become available.
> Q: “Ah yes, but how do you do code reviews?”
> A: Pair Programming is my preferred approach. You get better code reviews and much more.
This answer dodges one of the most common reasons I see engineers using multi-day branches. I think it’s safe to say peer reviewing code is an industry norm these days. This in practice gets directly in the way of CI. There are compensating techniques, like merging to master prior to executing the build, but they’re obvious downsides to that strategy. I’m a huge fan of CI, and get as close to it as I can, but I can’t think of any team I’ve worked on where it would have been pragmatic to pair-programming every change. I don’t love it, but the best strategy I’ve developed so far is to ensure my teams put a high priority on timely review of changes and squash scope creep or bike shedding wherever it arises.
Loved the post!
Thanks, I am pleased that you liked it!
I think that wether you choose to see “Pair Programming” as a form of continual review or not is down to the team. I do. I think that PP is a better for of code-review, it gives you ALL of the value of a separate code-review except in-more detail, continually and has a whole load of side-benefits that in some cases are even more valuable than the review in the first place!
I sometimes get the push-back, “yes but I work in a regulated industry and so must have the review” – Me too! I have worked in several regulated industries under many different regulatory authorities. I haven’t found one yet that quibbled over PP not being a review. It counts as a review from a regulators perspective, creates higher-quality code and does so without slowing down the feedback cycle – I am sold! 😉
These days, pair programming isn’t the only good option for “continual review”. Duvall & Glover covered this nicely in their authoritative CI book in 2007 (from the same series as Humble and Farley’s CD book, but 3-4 years earlier). They did this when they introduced automated static code analysis into the CI pipeline (and called it “Continuous Review”). This drastically and repeatably reduced the amount of manual time and effort needed to review code changes (just like TDD and BDD did for testing). When you have a tool like SONAR or Cobertura or Panopticon (or JetBrains) that is able to automate systematic code-quality issues like design-quality, clean coding standards, code-smells, and the other various aspects of technical debt, it lets you better focus your “manual” reviewing efforts on higher-level things that don’t take as much manual effort.
You can defer/focus those manual reviewing efforts to so called pull-requests, and if you keep the changes small & frequent enough, even without (promiscuous) pair-programming, you can still do (promiscuous) pair-reviewing to leapfrog that code-review as quality-gate bottleneck.
The problem comes when the code-review encourages or enforces a form of handoff-to-specialty-role (i.e., buildmaster, architect, tech-lead or feature-lead). That creates bottlenecks and diffuses the “conquer and divide” approach of being able to collaboratively “swarm the solution” (instead of using a handoff).
Just to clarify, when you say JetBrains, do you mean their Upsource product? Are you talking about tools to automatically reject code that fails some quality tests, or just to auto inspect it and provide the results to reviewers?
Hi Barney! When I say JetBrains I was referring to their earlier products (an IDE in particular). One of them was IntelliJ, and specific to Java. I remember another one that worked for C#. Another popular one for C# was “resharper”. I am referring to tools that do static code analysis (as opposed to run-time analysis or monitoring), that are able to analyze the code structure and dependencies and flag warnings & violations of conventions and rules in areas of note just coding-standards, but memory management, security, DSM, code-smells, and even suggest refactorings, and (more recetly) report a deyailed mulit-component measure or index of maintainability and technical debt (e.g. SQALE).
These tools automatically review/inspect the code based on selected and configured rules (and their plugins), and then raise a warning or error-level as a return value, which can then be used by a CI/Build system to flag success or failure along, and report the results along with optional vs mandatory remedial actions.
If pair programming everything isn’t an option, and code review is still wanted, I wonder whether it’s better to do a typical pull-request to master workflow, (with of course less than circa seven business hours between branching and merging), or push directly to master and then have a peer review it later.
I’ve only ever worked with the former. Post-merge review seems attractive, but then I’m not sure quite how that would be organized and what happens with the feedback. If it’s a suggestion for a maintainability improvement does it get dealt with, and if it’s feedback that says the change will break prod does that make a discontinuity of delivery? Or does the reviewer immediately revert the commit?
This particularly important if there are not sufficient automated tests, so a coding mistake has realistic potential to cause a production bug.
I have tried both of those. What I found was that as the rates at which commits are made increase, the temptation to “cheat” the system grows. What I have seen is developers making “pacts”. “You can sign my name to a commit, and I will sign yours”. Not good 🙁
I have tried to build the review cycle into CI systems, using some of the well-known code-review tools. It is OK, but not perfect.
To be clear, you can make either of these work. In my experience though Pairing is much the best solution to these problems. I would question why PP isn’t an option. If you have a practice that allows you to go faster and create better code with fewer bugs, why would you not choose that?
In my clients I try to treat any push-back on pairing as demonstrating a need for education, rather than demoing that pairing is inappropriate. I don’t always win the argument, but I always try 😉
Thanks Dave. I will take your advice about questioning why PP isn’t an option. I can’t answer it here since I’m not asking about any one particular situation.
I suppose one reason for PP not being an option, from the perspective of someone who isn’t a tech lead or CTO, is I might not be able to persuade someone else in the team or organization that we should do full time PP, even if I could persuade them that we should do CI.
Hi Dave,
Interesting read! I’ve tried both approaches and I think both can work. Of course you make no mention of temporary branches that CI tools can create so your feature branch can be tested in the trunk.
I’d also like to tell you how influential your ideas around acceptance testing, DSLs and mocking out dependencies have been. So much so I’ve taken this idea and bought into it wholesale on the last few projects I’ve worked on. The feedback is as liberating as you say.
Current setup uses docker to create a transient environment, complete with external message bus, wiremock for numerous external web APIs, DB container, etc etc. This all runs thousands of black box tests in a manner you describe in your videos. The key is that it all happens BEFORE the code is merged to master.
This means our short lived feature branches can experience a rolls royce test suite and get early feedback before hitting trunk.
I wonder how you think this fits into your idea around the friction of extra branching?
I should say we pair programme (it’s the best way) AND do code reviews. We write better software together and we catch bugs and simplify designs in code reviews. I like the safety net of people looking at my code and I learn things when I see how they write theirs.
I’m also an ardent believer in “rough-cut” code review. Am I/are we heading in the right direction/barking up the wrong tree.
I personally have drank the kool aid on this approach. It’s like a drug and I know colleagues who say the same. There was a sea change in the way developers worked. They stopped manually poking the app and started writing acceptance tests to check it was working.
It’s my guess that when you talk about feedback you’re assuming unit/functional tests run in CI which deploy somewhere only when merged to trunk. This probably kicks off a pipeline which deploys to a test environment against which a suite of acceptance (system) tests run against the new version.
If this guess is correct (I might be way off) I would like to know if you’ve tried the “Farley Approach” to testing with transient environments which run per branch? If you have: what do you think of this approach?
If you haven’t: please do so and then do a talk about it 😀
Yes, both can work, but I think that there is a difference. I can choose to ride a motorbike, standing-up, facing backwards or I could sit down and be more cautious. I may get away with the first approach, but it is less-stable, less reliable and if things go badly, they could have big consequences. Just because I got away with it once or twice, or even twenty or a hundred times, doesn’t mean it is as safe and stable as sitting and working the controls with my hands.
Yes feature branching can work, and works a lot more reliably than riding a motorbike standing-up facing backwards, but it is not as stable, or as safe, as practicing CI. The data says that in “High-performing teams” you are much more likely to find them practicing CI than you are to see them working on feature branches (see reference in blog-post for source).
I am pleased that you have found the acceptance testing and DSL stuff useful. I find it goes down very well with the companies that I consult with. This approach works fine on Trunk too 😉 You do have to keep the performance of your feedback good, care about the efficiency of the tests themselves and scale out the hardware that they run on, but you can do all of this in a truly MASSIVE scale if you need to.
Yes, each change to Trunk kicks of the pipeline. I refer to this as “Giving birth to a Release Candidate”. The pipeline’s job is then to “prove that a Release Candidate is NOT fit to make it into production”. We treat the tests, all of the test (Unit, Acceptance, Performance, Analysis, Security, Data-Migration ALL TESTS) as a falsification mechanism and reject the Release Candidate if any test fails. The trick is to be able to run all of these tests multiple times per day. I generally recommend that people aim to get definitive feedback from all of these tests in under 1 hour. Sounds impossible, it is not, but it can be demanding!
The problem with running any tests on a per-branch basis is “what are you evaluating”. If you are running on a branch you are, by definition, testing a different set of code to what is on master – otherwise the branch has no point. This means that you are testing a set of code that won’t end up in production. At best, this is inefficient, at worst it is misleading you. If all the tests pass on the branch what does that mean? It doesn’t mean that it will work in production, you still don’t know until you have merged your changes with mine. My changes may break your code. So we have to run the tests again when we merge – slow and inefficient!
Thanks for the feedback!
[sigh] Dave, your statement that feature branching can work but “is not as safe or responsible as CI” is again making the false assumption and false dichotomy (there is no forced choice between feature branching versus CI, neither precludes the other nor does it have to hinder the other). It can be an *and*, its its not a matter of luck or circumstance, but a matter of discipline.
Your mantra of red-green-refactor-commit (where “commit” implicitly means integrate+build+test) is independent of branching, It is not delayed by the correct+disciplined use of branching, nor does it add more/superfluous steps.
IF you are committing to trunk every day, why make a branch at all?
I have yet to hear a good reason to make a feature branch that lasts a day or less…
Hi William! The “IF you are committing to trunk every day why make a branch at all?” question has been addressed within previous replies. I’ll try to call them out.
Regarding so called “mayfly” branches that live no more than 1-day, Dave and I are both in agreement that there seems to be no good reason to create those. It doesn’t give any indication of the granularity of a feature/story, and in addition to having a commit-on-trunk for every merge, you also have a branch for every one of those commits that has no added meaning/value beyond the commit-itself (and the added overhead of not just creating them daily, but deleting them daily too, which just confirms they were waste in the first place).
When it comes longer-lived branches that last the duration of a small feature (or agile user-story), then as long as they are merged to trunk at least daily until the feature/story is complete, I would argue those branches *are* the most useful to create. It visibly declares and transparently reveals the intent the codebase (instead of it being hidden in the local repo/workspace) and as long as you still commit+integrate to trunk every (until the feature/story is completed) it clearly indicates the flow-structure *and* granularity in the commit-graph.
The key here is that frequency of merge-to-trunk does NOT equate to branch-lifetime. The anti-pattern in this case isn’t the creation of the branch, it is the failure integrate frequently throughout the course of the story/feature (Usually due to fear, or just lack of knowledge about how to breakdown the work into sufficiently small, buildable+testable chunks such as with TDD/BDD ).
Where things get confusing is when the granularity of change to merge/integrate is different from the granularity of functionality to be deployed/released. If there is a valid business+technical reason to prevent release/deploy of partially completed feature (even if it currently passes all the tests and doesnt break anything) then too many will feel they can’t merge-to-trunk until the feature is complete (because otherwise they have to dis-integrate partially completed feature from the trunk).
But delaying integration (for that reason) is not the solution to that problem. The real problem is’t really a question of when to merge (or how long to delay integration), it is a question of *when* to make the functionality available in production. I can easily separate code *integration* from code *activation* by using later binding-time (e.g., toggles) that are activated (switched on/off) at the time of production deployment/installation/configuration.
First up, thanks for the thought provoking post! It’s definitely got me thinking this morning.
After a few re-reads, I’m still missing the connection between “CI is about speed and clarity of feedback” (which I wholeheartedly agree with) and “Any form of branching is antithetical to Continuous Integration”. It seems like that is based on the assumption that you are only running your CI on master? Why not just run CI against any commits pushed, whether it’s master or other branches or pull requests or what-not? Is there a technical reason that’s not viable, or is it philosophical? It’s certainly possible on all the major CI providers that I have worked with over the year.
Beyond that, it seems like the major argument is that “merging into master is hard”. That just sounds like a good argument for keeping feature branches short lived and regularly having master rebased into them. There are more and more tools popping up to force feature branches to be up-to-date with master before merging back in. Provided you can make guarantees about master being evergreen, it seems like it’s up to individuals to handle keeping up with master on their feature branches as makes sense for how they develop.
The huge advantage to branches and pull-request based development is that you can clearly describe what is being implemented over a series of time and collect feedback as you go. You can do it asynchronously, with a distributed team on different time scales. You have code reviews captured and you can do meta-reviews on them to help folks learn how to give better feedback and receive feedback better. Pair programming is great, but it shouldn’t replace those things, it should complement them.
My take is that different teams come in different shapes, and that CI practices come in different shapes accordingly. What works for one team size and composition doesn’t for another. I see the crux of CI as being continuous feedback, delivered rapidly and acting as a central source of truth for a team. I see branching as largely orthogonal to these concerns.
I am pleased that you enjoyed it, and delighted if it gets anyone thinking – that is always a good result whatever the outcome of the thoughts 😉
For me the link between those two statements is “A branch is, by-design, intended to hide change in one part of the code from other developers.”. We want branches for the isolation that they provide, we want Continuous Integration to evaluate our changes alongside everyone else’s continuously (or at least a close approximation of “continuously”).
You are right, the thrust is to recommend that we “integrate frequently”. The main point that I am trying to make is that there are better ways than feature branching to achieve that. Feature branching is intended to let you create a feature on a branch, obvious I know, but my point is that for CI, waiting until a feature is complete is too long to wait to see if it works with everything else. By changing the way that we work, by “embracing change” as Kent Beck said, and working in tiny, incremental steps towards the creation of a feature we eliminate the need to branch. It does require us to change the way that we work, but when we do, my subjective experience, and the data, says that we create better software faster!
I don’t believe that this is a “teams come in different shapes” kind of thing. I think that there are some software engineering practices like TDD and CI, and I place both firmly in the engineering discipline camp, that have such a profound impact on quality and productivity that they are not really optional. Or at least, when a team chooses to do something else the choice that they are making is “we are happy to create lower quality software more slowly”.
I recognise that this is a very hard-line statement, but it is what I believe to be true. I think that there are some disciplines that are so effective and so well-proven that they should be part of the definition of what “professional software development” looks like and for me CI (and TDD) are firmly in that camp.
The problem isnt that its a hard-line (and opinionated) statement. The problem is that it is wrong, because its premise is false (which in turn is predicated upon false assumptions).
“Waiting to see if a feature is complete to see if it works with everything else is too long” is a correct statement. The assumption that creating the branch always implies such waiting is very much false, as is the assumption that using such a branch makes it take longer to integrate frequently/continuously. It doesn’t.
What about rebasing master to the feature branches regularly, maybe even after each merge into master? Then the feature branches would really only consist of their local changes.
Yes and if you really must use feature branches, this is what I would recommend. But I believe this to be very much second-best.
First, there is a temptation to stay on the branch for longer and longer. Part of the definition of CI is that if you are “Committing changes to master at least once per day”. If you rebase through the day and then commit at the end, well OK, but that is less efficient than working on TRUNK.
I want the lowest-possible friction to small frequent commits. That is, pretty-much, what CI demands of me. So I want to minimise the cost of committing changes. If I work on, even short-lived, feature branches I incur extra work, more steps in my process of committing changes to TRUNK.
If you don’t practice CI, and commit to master less frequently than once-per-day, you are running a big risk that you will get tripped-up by a nasty merge later on. The longer you wait, the bigger that risk. Also, while your changes are isolated on your branch, you limit the degree to which I, and others, can refactor the code – without killing your changes.
So I think that my argument for CI, in preference to feature branches, stands.
If everyone’s working on a feature branch, then master isn’t changing. In that scenario you don’t achieve anything by rebasing your branch on to master. You haven’t tested whether the code in your branch works in combination with the code in someone else’s branch.
Barney is correct. Rebasing from master (or trunk) more frequently means the developer (or pair) gets frequent feedback from the team’s integration branch. But it is NOT bidirectional. It does not make merging to main-trunk more frequent.
It does usually require less effort because the amount of change since the last merge-in (sync-up) should be less, and therefore less effort to merge out/up to main-trunk.
Okay – time for the other shoe to drop. While most of the initial post great stuff, there are still a couple fundamental statements or sentiments that are just plain wrong, the first and most fundamental being the following:
[FALSE] “Any form of branching is antithetical to Continuous Integration.” [/FALSE]
I know you and Jez having been saying this for years (and before that Martin), and Paul Hammant picked it up as well (and others since then). It was wrong then, its wrong now, and its always going to be wrong. That you continue to perceive all the arguments against as pushback is more indicative of the deeper problem.
The deeper problem is your current way of perceiving and thinking about branching. This is a limiting mindset (as opposed to a growth mindset) and is not only holding you back from a better and more useful understanding, but is doing the same for others too.
This mindset tends to think of branching from a “physical” perspective (of the code). But that’s not the actual dimension/domain where branching operates. Even a simplistic separation of branching “domain” into so called quadrants (like Agile Testing quadrants, or technical debt quadrants) can help expose the limitations of this mindset, along just two axes:
1. New/change Development vs Integration — Use of a branch for developing (in-progress changes) VERSUS integration (synchronization of changes from others)
2. Early (big up-front) vs. Late (Just-in-Time) — Branching early (project-based), for projects/releases, subprojects/features, and (sub)tasks VERSUS Branching late (lean-flow), at the last responsible moment, when true parallel/concurrent maintenance (separate from the main-trunk) becomes unavoidable (often post-release, but sometimes shortly before (even if only briefly).
Your statement about branches being “antithetical” to CI is only true for ONE of these four quadrants (between 25% to at best 35% of the entire domain).
The problem is that most of the time you encountered (feature) branches, it was the dynfunctional usage, and usually referring to *early* branching of a feature *integration* (often for a separate feature-team). This limited you from being able to perceive other forms and uses in any other way, and in the rare cases when you do (shortlived for <=1day) you perceive those as exceptions or outliers. Rarely (if ever) were you ever called in to look at the branching usage of a project with more than one codeline that was doing it effectively/right, and not causing unnecessary integration delays. So you see the problem-space as very much black-and-white.
The problem is NOT the branch. It is not the branch that limits or discourages people from working and committing in smaller and more frequent (micro-sized) chunks. Whether I do (new) development changes multiple times a day is not made any harder or less likely by integrating them from a workspace on its own stream/branch versus the main-trunk. (In fact, making many small/micro-branches [i.e. one per change-task] is more overhead to create and retire each branch micro-branch then to integrate them all from the same stream in short+fast+frequent increments.
It is not branching that is antithetical to CI, it is failing to integrate frequently that is antithetical to CI. The fear or risk of merging functional subsets of a feature (in working+tested chunks) had nothing to do with whether a branch is created or not. It has *everything* to do with concern over delivering partial/incomplete features (even if what complete so far is fully functional). This has nothing to do with branches or branching. It has everything to do with business-decision and funding-model regarding fixed-vs-flexible scope. This is what motivates branching/toggling at install-time or run-time (in the code) instead of earlier binding-time (in the VCS).
Stop blaming the branch (or the vendor, e.g. IBM/Rational). The problem is the mindset around the incremental integration of features being all-or-nothing when it shouldn’t have to be. Whether you solve it with an additional VCS-branch, or an additional-code toggle, you are still adding substantial complexity to the integration-structure and/or code-structure that makes it less “clean” (and less well “factored”) and introduces more technical debt.
I would go so far as to say that 80% of the time, the right answer to the question of branch-or-toggle is *neither*. Just integrate very frequently and using TDD/BDD and refactoring (and if you use toggles, don’t exempt them from refactoring).
So the correct advice here is NOT “don’t branch X 3”. The correct advice is the same as Dijkstra’s laws of premature optimization:
1. Don’t do it!
2. Don’t do it (yet!)
This is true for BOTH branching *and* toggling (and even parallelization of algorithms). Instead, Defer the irreversible decision to the last responsible moment (when the cost of delay crosses the critical threshold). Sometimes that means making the decision reversible somehow (by adding another level of indirection, *possibly* at later binding-time). But until then, keep it small, incremental, simple, sequential, and integrated as frequently as possible.
The other thing to remember about frequent feedback, is that it applies at ALL levels of scale. Which is why we have multiple feedback loops at multiple levels. Sometimes adding a branch (or a toggle) IF DONE THE RIGHT WAY, does not delay feedback at the current-level but adds an additional (outer-nested) feedback-loop at the next-level-up (where you might not have had one in place already). This is where you might add a branch while still integrating just as frequently (rather than instead of).
Hmm, not sure how to respond to that. I start out disagreeing with what you say, I still think that I am right that CI and FB are antithetical, one is about exposing change, one is about hiding it. I end up agreeing with you, or you and Dijkstra, “Don’t do it! Don’t do it yet!”.
I talk about toggling in another post, and come to the same conclusions that you mention here, it is a practice of last, or at least late, resort.
There is good data that FB doesn’t work as well as CI, but you are right that what that data says is “failing to integrate frequently” is the real problem. But software development is complex and is a human discipline (or sometimes a human ill-discipline ;-)). As such there are complex effects, there are human behaviours that need to be taken into account. If we “integrate frequently” from branches, there is an overhead, we have more steps to take. They may be small simple steps, but there are more. As humans, we tend to be lazy. If there is more work, we will avoid it one way or another. What I see, and read, and hear reported back from friends and colleagues, is that what most teams end up doing is delaying the merge. So the (small) extra cost of branching applies a small pressure to delay the merge so works against your “frequent integration”.
CI is a strategy designed to maximise that integration. Again, any impediments to the process of committing, and evaluating, change will tend to make us integrate less frequently. So, over the years I have become obsessed with the efficiency of this part of the process. I want the minimum number of steps to commit, I want my builds to be as fast as I can achieve, my tests to be fast, the feedback from the CI to be efficient (I prefer Team Displays to email for example). I want to optimise EVERYTHING to reduce the cost of a commit and so reduce the barrier to frequent, small changes. For me that is what CI is really all about!
If your branches live too long, you are not getting feedback regularly enough (“failing to integrate frequently”). If you are integrating frequently enough, the extra steps associated with a branch seem superfluous to me and so are waste.
The statement that “a branch is, by design, intended to hide change from other developers” is FALSE. Isolating work is not the same thing as hiding it. Branching is not the same as information-hiding, it is a form of isolating/separating concerns, not hiding them. (Just like “information hiding” is a form of encapsulation, but not all encapsulation is about information hiding.)
Separation of concerns, and hiding concerns are different things. We usually want to expose the separation (not hide it). We arent minimizing change (nor its frequency), we are instead striving to minimize the (economic) *impact* change (and change-frequency) using forms of isolation (encapsulation) to achieve separation of concerns. A branch encapsulate one or more changes by isolating them in a separate version-container. It does not hide them, nor does it prevent them from being merged frequently or easily.
Also, the statement “If we ‘integrate frequently’ from branches, there is an overhead, we have more steps to take” is FALSE, and is predicated on a false assumption.
There are no more steps to take to integrate from your workspace to main-trunk, if you are on a separate development branch or not.
What you are hearing reported from teams colleagues etc. is being filtered through your incorrect assumptions/thinking, and is a different kind of branch (one for integrating, not development). Delaying the merge in this case is not due to extra steps in the merge-commit (there are none). It is due to having two-levels of integration (first to the feature-branch, then to the main-trunk). That is a legitimate delay, and also a legitimate additional merge-commit.
Be careful about optimizing commits/commit-steps as if they were synonymous with optimizing merging/integration-steps. They are not the same thing. Not every commit is a merge/integration. (And not every commit represents a working/correct state, much less an integrated one).
You keep shoving too many assumptions into the same statement. commit does not necessarily mean merge. Isolate does not imply hiding.
I agree about those assumptions being unnecessary if not plain wrong, and I have a feeling that they come from still treating DVCS as if it was CVS/SVN.
Interestingly, that seems to be a typical undercurrent whenever there is push against Feature Branches.
Github’s code review functionality is pretty terrible anyway. Somebody who builds a nice way for a team to retroactively code review work and maintain review coverage could win pretty big in this space.
Thanks Dave! Glad youre starting to absorb at least part of it. Lets address those (before I reply to your toggling post – which shares the same thinking-fallacies).
You write: “There is good data that FB doesn’t work as well as CI …”
Ive seen the data you refer to, from Paul H., on your CD blog (with Jez), and even later material from Nicole Forsgren. The problem is the data is no good – it shares the same wrong assumption (which is the assumption that lifetime of the branch is closely correlated to frequency of integration to main-trunk). This assumption is wrong, and the data used to infer that is in fact incorrect.
A. The data on this subject that fed into the last two years state-of-devops report makes the same wrong assumption. It doesnt include any data that looks at the actual frequency of commits-to-trunk from the corresponding development activity (regardless of whether the activity was done on a separate branch).
It assumes that duration of the branch is the same as the time between when the work started and when it was merged/integrated. This is a false assumption. If work is integrated more than once between those two times, the data that was collected isnt seeing that. It ALSO isnt seeing when work is integrated infrequently WITHOUT having a corresponding branch.
It only thinks work is being committed frequently (or not) based on the branch duration, and not on the number of integration/commits between the activity start+end (even if it is at the granularity of a “story” rather than a feature, and especially if the story itself is broken up into smaller dev-tasks that are each integrated).
Pretty much all the data you’re referring to suffers from this problem. Which is exactly why your next statement (“if your branches live too long you are not getting feedback regularly enough”) is utterly false/incorrect.
The problem is neither the branch NOR the lifetime of the branch (at least not when it is a *development*-branch). The problem is failure to break-up the work into smaller chunks that get integrated more frequently. This is *regardless* of whether the development work is done on a separate branch or not!
The branch doesnt make people and teams worse at doing that. If anything, the branch gives a better feeling of a safety-net to make it safer to commit to the repository more frequently (which is only actually true for a centralized CVS, since a DVCS like Git already gives the developer private versioning in the developer’s repo).
Branch length/duration simply DOES NOT automatically correlate to merge-commit frequency. All of your data that you think suggests otherwise implicitly assumes it but never actually demonstrates/confirms this. IN order to do that the data would have to be able to look at the frequency of commits-to-trunk on behalf of the feature regardless of whether that work happened on one (or more) branch, as well as whether or not it was distributed across multiple stories (and their (sub)tasks) on behalf of the feature.
Your next problem is thinking that minimizing the number of steps to commit is somehow equivalent to minimizing the time+effort to integrate to main-trunk. You need to look at the execution time+delays associated with committing *private* versions (whether or not they are on a branch, like in a developers Git repo), as well as the time+steps to sync and/or rebase your workspace before you commit to central-repo (on any branch, much less trunk).
The key things you are missing (and making implicit assumptions about) are *timing* and *usage*. Not all feature-branches are created equal, and you (and Jez, and Martin, etc.) have been assuming otherwise. There is a difference between a branch created for working/development (e.g., a new task, change, story) versus a branch created for the purpose of integrating/stabilizing shared work. The latter is a “codeline”, a form of “integration branch.”
The original complaint with the feature branches Martin and others had seen was the case of a feature *integration* branch. A single branch was being used to integrate/stabilize changes from multiple developers toward a single feature (regardless of whether they did their work directly on the feature-branch, or worked on a separate short-lived story/task-branch and then integrated to the feature branch).
This is VERY different from a development/working branch being used for a task, story, or feature. In the case of the story or feature, work still needs to be broken-down (and committed/merged) in smaller micro-sized chunks (and TDD/BDD are among the best known ways of doing this).
Creating an additional *integration* branch is what adds another level of integration-indirection between the development-change and the main-trunk. This is NOT AT ALL the case with a development/working branch. And the duration of the activity for implementing the entire story (or small feature) *will* correspond to the duration of a corresponding working branch (IF one is even created) but it does NOT determine if it is done in an incremental manner with frequent commits (nor does it make it more difficult, nor any less safe).
Lastly, you are also assuming too much is being “isolated” with a branch. The branch isolates work, but not necessarily people (or feedback). The way you end-up using the branch *might* do that, if you are not intentional or deliberate about it. That is not a matter of luck, but of intention and discipline (just like TDD, refactoring, and “simple code”).
I think you keep saying the same thing! It is not that I don’t understand, it is that I don’t agree. 😉
As I have said several times, and you have ignored, there are ways of working with branches where CI is possible, but when you do that you incur the overheads of branching for no real value. If you are merging a development branch to master multiple times per day, why bother with the development branch, work on master locally and push regularly from there. It *is* a form of local branch. I think that the thing that we can agree on is that frequent integration of your work with everyone else’s is the key enabling step to CI. After that the mechanisms matter a bit less, but from my perspective I recommend, for previously mentioned reasons, that you work to eliminate all possible waste from the process to make it as low-impact, and simple, as possible.
Hi Dave! Yes – I keep saying the same thing. I’ve been hoping you have a greater curiosity to learn and understand why your reasoning is wrong (based on false assumptions), than in maintaining a position (or at least learning and understanding why the assumptions being applied are false).
You write: “If you are merging a development branch to master multiple times per day, why bother with the development branch, work on master locally and push regularly from there. ”
Why indeed? For that matter, why bother with the overhead of having a local branch? Of course, when it is strictly local, when no trace of my in-progress effort is visible in the central repo, then it really and truly is hidden from the rest of the team!
You also wrote (correctly): “CI is a publication based approach to development. It allows me to publish my ideas to the rest of my team and see the impact of them on others. It also allows the rest of my team to see, as it is evolving, the direction of my thinking.”
There is much talk of feedback, and of the rest of the team seeing (and being aware) of the work that is taking place. And “publishing” your changes to the central repository very visibly provides “intention-revealing” transparency to the rest of the team!
Here’s the thing: I get all of this when I publish my in-progress work to the central repo (using intention-revealing names/comment for each commit, tag or branch). This is true *regardless* of whether my last commit was to a separate branch or main-trunk.
There is certainly additional (and valuable) feedback when I *impose* my changes on the rest of the team by overwriting the latest commit on the shared integration-branch. But we don’t want to do that when we’re not yet at the appropriate point in our red-green-refactor cycle (that would violate the Beck’s rules of “simple code”).
Do you truly want to “hide” your work from the rest of the team before its finished? Or do you just want to *isolate* your work (but still visibly) before you have confidence/trust that it won’t have a harmful impact?
You already said we don’t want to hide work/change from the team. We want to isolate and contain any non-trivial harmful impact, while still making the work visible.
But if your work is *only* visible in your local workspace and not visible in the central repo, then it is effectively hidden!!!
The answer to why others want to “bother with a development branch” (even if they merge to master multiple times a day) is because it makes the work-visible (in the central-repo) and clearly reveals the intent (e.g., by naming it after the corresponding task, story, or even feature).
This is the entire justification for the overhead of *creating* the development branch. Because it transparently *exposes* the work-in-progress (instead of hiding it in the local workspace).
In fact, neglecting to do so *delays* the feedback of making that work visible, and for others on the team to notice it when they view any recent changes to the repo structure or history.
Creating the development branch does NOT hide the work, NOR delay feedback to the team. In fact it does the opposite! It visibly exposes the work-in-progress, clearly expresses its intent, while still isolating the *impact* of the change.
The purpose of a branch is the opposite of hiding work or delaying feedback. It is to isolate the work to minimize the impact of in-progress change while making it visible in the central repository.
From that point onward, there is no “extra work/steps” to commit the changes to the central-repo nor to merge them to main-trunk (any decent git-client, or vcs-client, takes care of that, not to mention any decent CI tool).
There is no delayed feedback, no hidden work, caused by the branch itself, nor by creating it. All those opinions, experiences, reports to the contrary are based on FUD stemming from misinformation, misunderstanding, and false-assumptions.
There is still the problem of adopting the necessary discipline to overcome ill-informed mindsets and fear/concern (both reasonable and unreasonable).
But you have to fix those wrong assumptions, the gross over-simplifications, before you can understand the real problem and the real issues & problems.
– branches make work/intent *visible* (they don’t hide it)
– branches *isolate work* (not feedback)
– commits are feedback/publication, even when they aren’t merge-commits
– branch length/lifetime does *not* correlate to reduced integration frequency
– development (work-in-progress) branches are *very* different from *integration* branches
– feature *integration* branches most definitely *do* delay integration (feature/story/task *development* branches do *not*)
– delayed integration is usually due to fear of commit-meant (with or without a branch)
“I’ve been hoping you have a greater curiosity to learn and understand why your reasoning is wrong (based on false assumptions)”
Wrong? Or just something you disagree with. It would be better framed with data and facts to assert someone is wrong. At least Dave’s points are backed by research. And while you disagree with the research, you also make some assumptions about how the research was conducted that doesn’t match the data Nicole has provided on how the research was conducted.
It’s fine to have an opinion, and to stand by your opinion. But maybe it’s best to acknowledge it’s an opinion, and not “fact” – thus Dave isn’t “wrong”, he just disagrees with you, and has reason for it.
Well, here I am writing a reply 5yrs later to a reply that was 5 years late to my own comment. But here goes …
Michael wrote:
> “Wrong? Or just something you disagree with.”
The former! i.e. just plain WRONG/FALSE.
(And trivially/provably so as well).
There is a single, very clear, very plain, very obvious FALSE premise is what Dave has written. That same FALSE premise is in the writing in the CD book, and is also referenced by the research in the Accelerate book by Nicole Forsgren & others.
The [FALSE] premise is this:
==> branch length/lifetime dictates integration frequency (FROM the branch TO mainline)
In other words, you must integrate (or ‘mainline’) your changes ONLY at the very end of all work on the [feature] branch!
This is PREPOSTEROUS! There is nothing in the tool forcing, requiring, or even encouraging this! It is just plain silly! EVEN WORSE, it’s blaming branching/branches for something that is solely about merging (whether you work on a branch or not).
The SOLUTION is trivial: INTEGRATE your changes FREQUENTLY/INCREMENTALLY (even if the whole ‘feature’ isnt complete yet).
The solution is NOT ” don’t branch” (and, oh by the way, also integrate frequently/incrementally).
And the research from Accelerate back this up! Integration-frequency is what matters! (whether your working on main, or any other branch). You have to:
1. DEVELOP Incrementally, and
2. INTEGRATE Incrementally
[Note that 1 is a pre-req for 2]
All of that is FACT (not opinion). The only FICTION is the aforemention [false] premise about branch-lifetime dictating integration frequency.
There is ZERO data/research showing any such (causal) correlation (not in_Accelerate_ NOT wnywhere else). It was an unsubstantiated assumption [false premise] that was never properly questioned.
In fact, from previous correspondences I has with Humble and Forsgren (and Fowler) back in 2020, Jez even acknowledged that it never even occured to them to think of doing that:
–> Because THEY had never seen it, they never thought to even ask the question
–> Even worse is the additional assumption that if they hadnt seen it, this somehow meant it was rare/marginal (as opposed to simply not knowing how to even see it in the first place, much less not even thinking about considering it)
So, YES! The aforemention premise IS false!
The corresponding statements about branches (based on branch-length) are ALSO wrong!
[And it’s not just Dave, but all the CD book authors, and Accelerate authors, and even the great Martin Fowler]
That one simple, trivial, mistaken little assumption about branches and their length/duration as it pertains to integration-frequency.
— It was a presumed “forced” coupling between a branch and its merging
— but no such coupling exists NOR did any of their data show, much less support this.
That’s all it took to (mis)lead down the wrong path of thinking it’s better to HIDE your work/changes-in-progress (WiP) in your local repo, and/or with disposable rapid-fire micro-branches (one per commit).
All that, instead of simply:
A. [develop AND] integrate your work incrementally
B. make WiP visible (dont hide it!)
[BTW, ‘B’ is a key principle (or ‘way’) in all three of DevOps, Lean & Agile that applies every bit as much to flow-of-changes as it does to flow-of-work]
And, also BTW, the easiest+simplest way to do B is with either feature [e.g. long-lived] branches or else ‘private branches’. The resulting version-tree (or branches AND merges) remains much simpler and more streamlined, but without having to hide your WiP!
This article doesn’t reflect my personal experience with branches.
Firstly, you present feature branching and CI as mutually exclusive. They’re not. You’re creating a false dichotomy.
As other commenters have mentioned, the CI tool should be configured to run a merged version of a branch with master whenever a new commit is made to that branch. You get a new build with every commit, and the result reflects the state of the branch *merged with the trunk*, which invalidates both your major issues, namely “too late” and “too risky”.
I’ve worked in environments where we deployed multiple new versions per day to production and used feature branches (in fact, working on trunk was impossible as it was a protected branch). This invalidates the claim you make that feature branch invariably slows development down.
You might argue that we were carrying out extra work not needed and that we would have been going even faster by developing on trunk. I would disagree but that’s a longer discussion.
Thirdly, branching carries semantic information that your process looses. Branches tell a story of the work in a way that a linear history does not. My biggest personal issue with trunk development is that this information is lost. Even on project where I am the sole developer, I will branch and do a forced merge to show that the branch work is related and the commits should be considered together as a unit of work (even if the entire process has three commits and takes 20 minutes). This information is lost in a linear history, making it harder to understand changes made in the past.
Fundamentally, I think you mistake practices and principles.
The practice of branching is neutral, and basically irrelevant to the underlying principle here, which is to keep WORK IN PROGRESS to a minimum, and behind which I stand for both informal/personal and formal reasons.
Teams can have a shitload of WIP while developing on trunk by having quarterly or biannual release cycles (Been there, done that).
Teams can have almost no WIP by using branching (Also been there, done that).
You’re cargo-culting trunk development without understanding the underlying issue. (Or at least you seem to in your post. Having gone through “continuous Deployment” I know your reasoning is in fact much more sophisticated on these issues). The take-aways from the State of Devops report is “Good leadership matters”, “Reduce WIP”, “Automate”, “Couple loosely”. NOT “Don’t branch”.
The irony is I’m inclined to side with you, but I think the post lacks subtlety, is misleading and wrongly reasoned so I’m having to defend the opposite viewpoint!
I think that we will have to agree to differ. If you ask the people that coined the term “Continuous Integration” and established the practice in our industry, the agree with me. Appeals to authority aren’t sufficient though. I too have worked on projects with all of these approaches. One of the common factors that I have seen for the highest-performing teams is to work on Trunk! The data from the industry backs my claim (see the link in the blog-post).
Yes you can do any of these approaches badly. That is not what I am describing. At the limit, working on Trunk is, in my experience, the least risky and most efficient. Data seems to back that claim.
I don’t think that I “mistake practice and principles”. If you have drunk the Lean cool-aid, then limiting WIP *and* reducing waste are both important to an effective, efficient process. There are two things here, not one!
We can “have almost no WIP while using branches” but they can’t also, AT THE LIMIT, reduce waste while branching – branching needs more steps! If the branch is unnecessary, then the steps are waste. Even if those steps are simple and cheap, there are more. I am making the point that there are ways of working that make the branches unnecessary.
You said “the CI tool should be configured to run a merged version of a branch with master whenever a new commit is made to that branch”. Assuming that you mean run CI on the code in the branch, then, unless you are reckless, you are also running the build again when you merge to master? If so, that is waste, you are running the build and the tests twice instead of once, and so delaying feedback.
Hi again!
“If you ask the people that coined the term “Continuous Integration” and established the practice in our industry, they agree with me.”
I had those conversations with all those people back then (Martin even wrote the foreword for our book on SCM patterns). And with the Poppendiecks (who agreed the issue was un-synchronized work). And with Duvall and Glover. (I was also a reviewer for your book too).
All of that was before Martin popularized “feature branch” with the wrong definition. Feature *integration* branches are usually a bad idea (there are some limited cases, when the biggest obstacle is concurrent-commit-contention during the integration+build time-period [when it can’t be more easily resolved by other means/HW]).
But then term grew to gross misuses, and wrongly included even *development* branches (for small sprint-sized features) and then all branches (even when still integrating frequently). [Pretty ironic considering the exact same thing happened to the term “Refactoring”, and Martin was the one who most famously published “Refactoring Malapropism”]
Martin even went on-record in Adam Dymitruk’s (in)famous blog-entry that he had been previously unaware of this other (*development*) usage of feature-branches. And he significantly updated his bliki entry at the time to clarify, as well as the perceived reasoning/intent for why those using the long-lived unintegrated feature-branch didn’t want to merge (it wasnt because of the branch, it was the mindset around merging all-or-nothing, and the fear of incremental/partial implementation on the main-trunk).
Even yours and Jez early articles on the CD blog in those days was referring to the wrong (oversimplified and incorrect) definition but still at the correct (ab)use-case.
Then you and others (including Paul H.) started overgeneralizing the problem (and the causes) due primarily to a fundamental misperception of branches as operating at the physical-level of a codebase (which is untrue) as project-oriented constructs (which is often true).
Some better commercial tools popularized the notion of a branch as a “stream” (rather than as a project or subproject), which is in fact the proper mindset for thinking and using branches, and is exactly aligned with lean thinking (and principles of product development flow) regarding flow and WIP.
And throughout this blog-entry (in the post, and in the comments) you are not allowing yourself to break out of your existing mindset. You keep saying “you disagree” and then keep referring to the same false assumptions and false dichotomies, rather than allowing yourself to realize where the actual boundaries and limits are.
And its all too easy to continue when you keep seeing branches ONLY in that limiting way, and dismiss the other as merely *possible* but lucky/risky/wasteful, In fact the opposite is true, and you are missing the majority of the purpose and utility of a branch (especially from a stream-oriented perspective instead of a project-oriented one).
The harm is that your recommended alternative (feature-toggling) is also growing in misuse/abuse/overuse, to the point where its causing a lot more overhead/waste/harm than the thing you are trying to steer them away from in the first place (when done improperly).
Granted, showing them the right way to do it, in the right context, for the right reasons – is extremely helpful. But it goes both ways! You also have to acknowledge and show the right ways, context, and reasons for branching (as well as toggling), rather than further repeating/spreading/teaching wrong information.
You need to talk about timing (specifically binding-time), and about delaying execution (rather than integration), and fight the real problem to get the right mindset.
I’d certainly prefer to work like that, but i don’t see how you would work on an application with a user interface without feature branches. Of course it’s easy to break a view into small components that you could commit without breaking things, but you wouldn’t want to merge that into master until it’s complete.
Lots of people do!
There are a variety of techniques that can help, Dark-Launching, Feature-Branching, Branch-by-Abstraction spring to mind. This is a normal approach for many teams, in fact most of the BIG websites work this way.
Thanks for the article. Good read.
Imagine I break something kinda subtle from “far” away. I go home, 2nd, or third shift developer or tester gets stuck cuss of the thing I broke. They may lack the domain knowledge to fix it and their progress is halted. Maybe they’d simply revert the changes, but a series of other changes that depend on my subtle breaking change have also been committed. — Yeah yeah, this is real doom and gloom stuff. Hopefully a software system isn’t so fragile, but imagine a system that is so fragile yet trying begin to adopt some of the practices you’ve described here.
>Each change is itself atomic and leaves the code in a working state, meaning that the code continues to work and deliver value.
So, I’m putting together some new feature, I got a red light on test. I’m able to or nearly able to green light the test, that is to say I have some time invested in the feature. I realize the only way to make the feature work is to change another interface and in turn everything that uses that interface. My shift is over, I gotta plane to catch or whatever. It seems I got no way to bank my non-working-state changes.
>If we do break something the build stops and rejects our change, that is the heart of CI.
Very curious of implementations of this mechanism. Build works on my machine, but I’m running windows and the build server is running linux. How’d the build server get the new code if it isn’t committed, or am I missing something else entirely?
Thanks for your consideration.
Ben, there are a collection of things at play here. Not least the discipline that surrounds CI. So you don’t “go home and leave someone else with the problem”. You commit your changes and wait for them to pass, before you go home. That way you don’t leave problems for someone else to tidy up.
Teams that practice CI and CD tend to commit changes frequently, throughout the working day. Mostly people will commit their final set of changes at the end of the day, as the last thing that they do before leaving, wait for the results and only then go home.
If you have to leave to catch a plane, and don’t have time to wait for the build, you don’t commit your last set of changes, but you have been committing regularly all day, so your last set of changes is only ever a few lines of code. When you come in the next day, commit them then, and wait for the build to complete before moving on to the next thing.
Teams operating CI will have a shared build-server. You commit your changes to the VCS and that triggers the build of your software and runs any automated tests that you have. If it passes – cool, move on to the next thing. If not, I recommend that the team adopts the discipline of committing a “fix” within 10 minutes. You either commit a fix to the bug that broke the test, or you commit a reversion of your changes so that you can think about what went wrong.
The discipline is to “keep the build in a permanently releasable state” so any failure, you drop everything else and fix it!
I am sure that this “don’t branch” proposal could work sometimes, and if this method is a good fit for a team and for a project, that’s fantastic.
But to shout out, “Don’t branch!”, in a one-size-fits-all ways is bad. And the troubling part is that I have no doubt that people who shouldn’t be paying any attention to this – which is probably many if not most teams – will instead hear the new Holy Grail, on the basis of nothing other than Dave Farley’s say-so.
But I also have some specific objections.
1/ Git History.
As a hypothetical future maintainer of a code base, I don’t want to see the evolution of someone’s thinking broken up into 15 minute intervals ; that is not interesting to me at all. It also strikes me rather as an abuse of the version control system. What I do want to see is working features and their readable source code squashed in as single commits, along with their tests and documentation ; and I want to read about what the author did – and why – in the commit message. I want ‘git show’ to tell me all of this quickly.
I don’t enjoy doing Git Archaeology when I could spend that time writing code. I bet no one else does either.
It seems to me that proponents of this methodology regard the revision history as either unimportant or someone else’s problem. It is not even mentioned here.
But here’s the thing. Three years after the fact, it might take a developer in the midst of a major refactor a lot of time to understand what happened during the 50 patches that add up to a feature, which could have better been squashed into one. But this time lost hasn’t been counted.
It might take this hypothetical “high performing team” 3 months to deliver the application ; even in 2 3/4 with this thinking. And then it might run for 5 years in production. Please also consider those on the 5 years leg of this journey.
This proposed workflow can only lead to an unnecessarily long, bloated, and confusing Git history.
And, in my opinion, the Git history is the second most important piece of documentation that a development team delivers, after the code itself.
2/ Cue for developers to not bother with commit messages at all.
This proposal will probably make 1% of developers faster and, in my prediction, be a cue for the remaining 99% to not bother with commit messages or documentation – which is, let’s face it, what they wanted to do all along.
“Who writes commit messages anyway”, says nearly everyone. “Who even writes comments in their code? Documentation is for the weak, for people who can’t write code that is so elegant and clear that only a lesser programmer would not immediately understand its meaning. And who cares about lesser programmers?”
After all, if a developer is expected to commit every 15 minutes, they can’t seriously be expected to put effort into documenting their changes, can they?
3/ What’s the big hurry, anyway?
The article asks:
“Ever got to merge some change that you have worked on for several days or a week, only to find that the differences are so great that you can’t merge? Lots of teams do find themselves in this position from time to time.”
So, it’s not only me who considers these merge conflicts to be rare events. This makes me think that the problem we are really trying to solve is just the optimising away of a couple of git commands to create and merge branches. That would be, in my experience, the main saving on a day to day basis.
If a team is already doing the full red-green-refactor version of test-driven development, that team is going to moving pretty quickly, and has a whole lot of early-feedback already – also known as the tests – so the team’s velocity is probably incredible, especially relative to the vast majority of other teams who can’t or won’t even write tests.
How did we end up in a place where optimising away those little steps – which, to be honest, don’t bother me at all – is more important than the Git history?
I also wonder, if saving on these Git commands is so important, if optimal design decisions would be made along the way. I don’t think this rush is consistent with good design personally.
So I am questioning the value system underlying all of this. When I read articles like this one, it seems to me that Agile has clearly just gone too far.
4/ Back tracking.
Maybe I am just not brilliant enough at writing code, but I sometimes find, after sleeping on an idea, that the code I wrote yesterday can be improved by doing it a different way.
At this point, I will just discard the old branch and start again.
That’s not a possibility if I have already committed onto master though.
This leads onto my fifth point:
5/ Less than brilliant coders.
The vast majority of computer programmers are not super geniuses, but people who actually struggle to write and design good code.
So how does this system work if we have a number of developers who need guidance? What happens if I am a team leader and I find I’m continually seeing code appear in the master branch that I simply don’t agree with, and would like reworked.
6/ Pair Programming.
Okay, no doubt you would say “pair programming” should prevent bad code going into master.
The big, de-emphasised presumption here is that everyone actually does Pair Programming, when of course most teams actually don’t.
There are many reasons why teams may choose to not do Pair Programming, including budget, company policy, personal space, sexual harassment, remote or offshore workers etc.
So this will mean in practice that most teams who heed this advice to commit straight to master will also not do code review.
Conclusion.
In summary, it seems to me that this workflow might work in certain teams and in certain circumstances, whereas I doubt it’s a good fit for most teams, and I doubt it’s a good fit for even a big minority of teams. I also question if it will encourage developers to not document their revision history ; get into a bad habit of rushing ; and commonly create problems when code gets into master that simply shouldn’t have been committed in the first place.
Well I agree with you about your first point. No one should believe what I say just because I say so! My favourite physicist, Richard Feynman, defined science as “a belief in the ignorance of experts”. I go along with that. I am recommending my theories for what works, not trying to be dogmatic.
I recommend that people try these ideas and see if they work better for them. Data from the industry, and my experience, and the experience of many many people that I trust to do good work, agree that these practices work better than the alternative. That is not enough – try it and see if it works for you before you rubbish the idea!
My point is a bit deeper than “this is one good practice” though. I believe that good, high quality feedback is the most important thing in the creation of world-class software (or any good software really). So I will compromise other things to achieve that. Branching, any for of branching gets in the way of that fast, high-quality feedback and so I will always work to minimise its use.
Yes, I don’t think that there is much value in the change-log as a maintenance tool. It can be useful, vital, in some circumstances (compliance-driven orgs, regulated orgs) but I think that if it has a significant role to play in understanding the code, it is saying something important (and not good) about the code.
I think, if you forgive me, that you explain your position by saying that you think it the “second most important doc, after the code”. That suggests to me that you don’t have good tests. If you did, I think that you would believe that the tests and code were close to equal (though code is first) conversations and shared understanding comes next. Comments in the code (maybe) come after that. Only after all of that am I interested in the Commit comments. Commit comments, for me, come a very long way down the stack!
I may be interested in them for other things, understanding team dynamics, keeping an eye on the commits of Juniors (so that I can help them if they get lost). I never rely on them to understand the code.
You are right that it is possible to use feature branches and deliver working code. My problem is that it is, in my experience, riskier than it needs to be. Ok, so merge conflicts are probably rare. That is, in part, a function of how long the branches live.
When the HP LaserJet team analysed their Dev process 10 years ago, they spent 5 times more effort, globally, moving code between branches than they did creating new features. I have seen companies crippled by merge-conflicts. So, yes, it can work (albeit with less efficiency than CI – read the data linked to in the post) but it can also end up in a terrible mess. I prefer to avoid the risk.
CI does not prevent you from waking-up the next morning and changing your mind. In fact I believe that it quite significantly enhances your ability to do that. I work this way because, combined with the other disciplines like TDD and Pair-Programming, I create significantly higher-quality code than if I work alone in large batches (features).
I don’t assume that everyone practices pair-programming, but I think that they should. (I have another blog post on that topic here).
This isn’t about being “super geniuses” it is about working in more disciplined ways that enhance our skills. I believe that the practices of TDD, pair-programming, CI and CD represent, collectively, an “engineering discipline” for software. Combined, they amplify the talents of anyone, whatever their level of skill, who practice them. That is what “engineering” is for – to amplify craft.
I am afraid that data and experience is against you, there are teams across the world in all different kinds of industry sectors, types of software, technical stacks, combinations of people and levels of experience who write better software using these techniques.
Hi Dave,
Thanks for taking the time to respond.
1/ Your response makes it even clearer that, actually, you really are writing for teams of super-geniuses, or at least teams of bleeding-edge, highly competent developers.
And you actually say so:
“…I believe that good, high quality feedback is the most important thing in the creation of world-class software (or any good software really).”
Now, maybe I am aiming too low, or perhaps I am battered and embittered by different experiences, but most organisations are not creating world-class software, and they’re not even aspiring to do so. Most are writing run-of-the-mill software that does a job, and most have hired devs of average ability.
I am sure we can agree that, these techniques – in the absence of programming ability do not write better software. Surely, you would agree, that what you mean is that better programmers write better software, and these techniques often help them.
The hardest part is always going to be actually writing code. Surely.
2/ I wish you could be more explicit about the fact that Pair Programming absolutely is a dependency, not an optional add-on, to this method.
I believe you have stated that clearly right at the end when you write,
“I work this way because, combined with the other disciplines like TDD and Pair-Programming, I create significantly higher-quality code than if I work alone in large batches (features).”
This is an important point because, regardless of whether everyone “should”, and I don’t necessarily disagree, but you know that not everyone does. And not everyone can.
Clearly, this method isn’t going to work in the absence of Pair Programming. Surely?
3/ If I may respond to this:
“I think, if you forgive me, that you explain your position by saying that you think it the “second most important doc, after the code”. That suggests to me that you don’t have good tests. If you did, I think that you would believe that the tests and code were close to equal (though code is first) conversations and shared understanding comes next. Comments in the code (maybe) come after that. Only after all of that am I interested in the Commit comments. Commit comments, for me, come a very long way down the stack!”
So, no, that’s not quite right. In fact, I simply included the tests and the code together in my mind. If you wish to consider them separately, then absolutely, I agree that tests are way more important than the change log.
But with that said, I would also note that, yes, the vast majority of devs actually don’t write good tests. In fact, many don’t write tests at all.
In any case, and for whatever reason, some changes to code bases will not be obvious.
If that’s the case, the choice is to not recording “why” the change occurred at all (which is of course what the vast majority of coders will do, but that’s because they’re lazy) ; or alternatively:
I can’t imagine where it could be better be documented than in the log.
And I think the problem is, again, is that you are only hired by the best of the best and this colours your experience.
I could be wrong!
I want to say more about this, after digesting it some more.
It was suggested that I try this method before I rubbish it. So, I didn’t rubbish it, by the way ; I just said that it’s not a one-size-fits-all. And if it does fit, then I like being pragmatic and doing what works.
To prove the point that this is no one-size-fits-all, I should mention that, at the moment, I am a remote engineer, and the rest of my team is in another country, in a different timezone. There is simply no possibility at all of having conversations, even phone conversations, or standups, pair-programming, or any of that.
By the way, I am rather a proponent of this http://asyncmanifesto.org
But back to this:
“…I think that you would believe that the tests and code were close to equal (though code is first) conversations and shared understanding comes next. Comments in the code (maybe) come after that. Only after all of that am I interested in the Commit comments. Commit comments, for me, come a very long way down the stack!”
So, I already agreed above about the tests, but where I strongly disagree is that you seem to be promoting tribal, undocumented knowledge as valuable, and even more valuable than in-code documentation ; and a well-managed Git history. You even seem ambivalent about comments.
Somehow you seem to be making a virtue of coders who are too lazy or impatient to communicate properly and document their code.
This all seems to be an extreme version of this https://martinfowler.com/bliki/CodeAsDocumentation.html
(which I entirely agree with, in the less extreme form).
You asked me to reconsider the way I work.
But I wonder if the Git (or other) change log seems to be mostly of no use, because yours actually is no use, because no effort went into making it useful. Just like a diary is useless if you don’t write anything in it.
I suppose you must know all this, but tools like Git Show, Git Blame etc are incredibly, incredibly useful tools when looking at code for the first time. It doesn’t matter a bit how clear or well-written code is. If the author of the feature Squashed their commit along with all their related code and documentation, you only need to see one line of that code, type Git Blame, and, instantly, all of the rest of the code for the feature appears, along with its documentation, and the annotations of the author.
If you are seriously claiming that this feature, this ability, is of no great use, then this is simply wrong. There is no way that anyone could be so brilliant at reading code, or any code base so clear, that this feature would not be helpful.
And so I return to what I wrote originally. How could the very large benefit of good documentation be devalued so far as to be worth less than saving a few seconds each day optimising away a few Git commands (branch, merge).
Now, I know that you can write good code – excellent, brilliant code – and not write a word of documentation.
What if the entire team is “hit by a bus”? What if this beautifully written application is then given to a completely new team to maintain? Now what is the value of tribal, shared knowledge? Obviously, it’s not valuable at all.
What if the key developers suddenly leave the company?
I really don’t like this message, because, I guess, I am so sick of working with developers who are too lazy to write documentation. There’s rarely a good excuse for this. That’s the truth. Yet, you’re making a virtue of it, I think, by stealth.
Alex, I wasn’t intending to be rude, but rather trying to make my point. If I have irritated you – Sorry! If I have made you think some different things, even if you disagree with everything I said, good! 😉
To be clear, I thought that your first post was reasonable, critical, and well meaning. I just disagreed with some of it. Let us proceed on the assumption that both of us mean well.
I too consider myself a pragmatist, a scientifically rational pragmatist to be more specific.
I had not seen the Async Manifesto before, the bit that I disagree with in that it “Comprehensive Documentation”. I suppose that it depends on how you read that, if you count code as documentation, then maybe, if not I disagree with the principle.
Documentation is an inaccurate representation of ideas. You and I have seen that in our mutual misunderstanding of one another during this discourse. I think that on many issues (e.g. automated testing) we are in closer agreement than we think.
Code is different. Because it is executable it needs to confirm to tighter constraints, so it is more precise in its description of what is really, rather than hopefully, going on.
So code is a more accurate representation of the reality of a system. I assume that we can agree on that?
The problem is that a lot of code is poorly written and so is difficult to read. So “documentation”, a less formal, less precise, more inaccurate, description is used to try and explain what is happening in poorly written code.
Another approach is to write better code!
The approach that I advocate is really focussed on that. I am not saying “just be smarter”. I believe that we have evolved a series of practices that in combination will improve the quality of any developer’s work, whatever their level of skill. For most of my claims I have data to back these assertions.
For me anstisepsis in surgery is quite a good analogy:
“The introduction of anesthetics encouraged more surgery, which inadvertently caused more dangerous patient post-operative infections. The concept of infection was unknown until relatively modern times. The first progress in combating infection was made in 1847 by the Hungarian doctor Ignaz Semmelweis who noticed that medical students fresh from the dissecting room were causing excess maternal death compared to midwives. Semmelweis, despite ridicule and opposition, introduced compulsory handwashing for everyone entering the maternal wards and was rewarded with a plunge in maternal and fetal deaths, however the Royal Society dismissed his advice.” (Wikipedia https://en.wikipedia.org/wiki/History_of_surgery)
I think that we are in the same state as surgeons in the 1850s. There is no reputable surgeon in the world that does not wash their hands before surgery now. This discipline wasn’t always obvious though. I believe that we have identified a number of practices that are the equivalent for software development of “washing your hands” was for surgeons. I describe these “despite ridicule and opposition” 😉
In both cases, existing practitioners, who don’t “wash their hands”, claim that this is unncessary and a waste of time.
Hmmmm, I like this thought, you have given me an idea for another blog post – thanks!
I am not sure if I am more extreme in my views than Martin (sometimes). What I will say though is that I am quite old. I have been writing code professionally for a very long time. I don’t say that to claim some kind of authority merely to point out that I have tried most approaches to development at one time or another.
I have worked in highly regulated environments and start-ups. I have worked in very large, big-ceremony dev processes and in tiny, fast extreme agile teams. As a result I have strong opinions (lightly held) about what works and what doesn’t.
For example: I treat commit comments as important things. I dilligently comment on every commit, even when working alone, and will often pause to think of a meaningful description of the change. I find them useful, but their use is orthogonal to understanding the code. They tell a different kind of story. They may let me hone in on a particular change, but I don’t expect them to explain that change, merely highlight that it exists and provide some navigational guideance through the information space of the code base.
The best code-bases that I have ever seen tend to have less, rather than more, documentation. There is a limit, of course. Documentation has a role, but if it is used to explain what code does, it is waste IMO.
Example (Which code is easiest to understand?):
Example 1
/*** Name: function
*
* @param s String parameter
* @param v int parameter
* @param p int parameter
*/
public void function(String s, int v, int p)
{
double r = (double)v * (double)p/100;
System.out.println(s + r);
}
Example 2
/*** Displays the the specified percentage 'p' of the supplied value 'v'.
*
* @param s Message to display
* @param v value
* @param p percentage
*/
public void function2(String s, int v, int p)
{
// calculate p percent of v
double r = (double)v * (double)p/100;
// display results
System.out.println(s + r);
}
Example 3
public void displayPercentage(String messageToDisplay, int value, int percentage){
double percentageOfValue = (double)value * (double)percentage/100;
System.out.println(messageToDisplay + percentageOfValue);
}
I would suggest that 3 is the best code. 2 is better than 1, which is rubbish. As a consultant I rarely see code that looks like 3, most code I see looks like 2. It is documented, be the docs don’t really help, and in real world systems of more complexity than this, the docs are usually wrong – they have drifted out of touch with the code. It is harder for that to happen in example 3. If I change the code to do something else, I am more likely to change to words (code) in example 3 than in the other 2.
If developers leave the company, the rest of the team brings new people up to speed, and works in a way to limit the risk of only one person knowing anything (back to pair-programming again, amongst other techniques).
My approach works. I accept that it may not be mainstream, but I believe that it is significantly better than other approaches that I have seen and tried. I think that we have discovered that “washing your hands” makes a big difference, but it requires a change in the way that most teams think about, and practice, development. The good news is that fewer people die (or at least few people have to live with low quality software) 😉
Hi Alex! I’m familiar with all the things you describe. And I don’t suffer from branchophobia nor branchogyny. And I like the value of simply understood (lightweight, yet literate) code and changes/tasks. I’m still a big fan of CI working in small task-based and test-based chunks, while still doing so in a “literate” way using available mechanisms in my SCM tools and in the codebase.
I used to be a proponent of checkin/checkout comments back when you had to do it per-file, but quickly grew to feel it was clutter as comments added up (inserted into the code) but were spreads out across files instead of all in one place. I liked it better when those notes/comments were associated with a single commit (across all files that participated in the change). I even don’t hate using a tracking tool (like JIRA or Trac) to track the changes at the task/story-level, including comments/notes.
However I’m still a big fan of working and committing changes in very small chunks and integrating continuously. And managed to do so for quite some time, in teams, while avoiding most of the problems you seem to have with it.
Pair programming is great in a lot of ways, but isn’t strictly required in order to still be able to do CI. You can still work in very small increments and do code-reviews via pull-requests and chat/IM. The more frequently commits happen, the more difficult it is to try and understand the story/logic behind a change – but then I find other/better ways of being able to do that (which can be supplemented by commit comments, especially when they reference a task in a tracking-tool and/or a section (or subsection) of a Wiki page where things like release-notes and/or change-logs can be easily compiled (even integrated) and captured.
S, you don’t have to skip code-review in order to do CI (it might not be quite as frequent, but it can still be frequent enough [i.e. multiple times a day per developer]. History and documentation are useful, but should not prevent working in a continuous or incremental fashion. I find automation and integration with wikis/workflow/changelogs a much better way to construct a logical flow of the rationale behind an overall change (even if it spanned the course of several commits from a TDD-style of working).
So, for example, if I have a corresponding user-story or “change-task” in a tool like JIRA or Trac, I might still use a story-branch (or task-branch) and still integrate frequently to the main-trunk after every red-green-refactor cycle (test by test), but still maintain developer notes/comments within the corresponding story object (be it in a wiki, or tracking tool, or possibly both, with some tool integration).
Plus there are many ways to integrate this into the workspace so it doesnt become a “tool context-switch” to compile/add comments. An in fact many tools like gitlab, github, bitbucket etc have integrated ways of doing this, including a reference between the commit and the story, logging commit-comments into the comment-log of the corresponding story/task or wiki-page, and Ive even seen use of a NOTES (or other file) in the codebase (often using markdown format) to integrate it into the codebase itself.
My favorite way however is when the SCM tool itself supports the notion of a “task/activity” or “job” that automatically pulls all those things together, even for a an activity that spans multiple (sequential) commits, with all the commit-comments, story-text, notes, sometimes even e-conversations associated with the task (Eclipse Mylin project had a nice way of doing this too).
And Ive also seen this done with task-branches (even when committing to the main-trunk multiple times during the lifetime of the task) all without impairing the ability to do CI in such a micro-incremental fashion.
Hi Brad,
Thank you for your comment.
Yes, I followed your interesting discussion of your ideas above, e.g. – http://www.davefarley.net/?p=247#comment-11433
I find myself completely in agreement, as far as:
– Do TDD (red-green-refactor).
– Don’t use long-lived branches – they are definitely problematic.
– Do commit early, and commit often (*more below).
– Do use short-lived branches, for isolation of your work.
– Do publish your intent often by pushing – and of course I strongly support the idea of “intention-revealing names/comments for each commit, tag or branch”.
– Do rebase often—for continuous integration & continuous, high-quality feedback.
You make an excellent point when you write,
“…if your work is *only* visible in your local workspace and not visible in the central repo, then it is effectively hidden!”
Absolutely. Incidentally, I have colleagues right at this moment working on a “spike”, I know they are not ready to merge anything, and here I am frustrated because they left for the weekend, whereas I want to review their thinking about the problem – as you say. So, because they didn’t push to their branch, I can’t see!
But of course, as you have noted, I am primarily motivated by Code-as-(Comprehensive)-Documentation. e.g. http://asyncmanifesto.org
Now, your comments are interesting to me, because I start to wonder if I take my own Git knowledge for granted. Since I have only 10 years experience as a “real developer” (I was a sysadmin before that), so Git, and the Github/Travis CI/Issues/Wiki integrated stack – or the similar Jira/Confluence/Bitbucket/Hipchat stack – these incredibly powerful tool-stacks are all I know.
At the moment, I use Atlassian Cloud. So, here’s a bit more detail about my workflow, to illustrate how it all “comes alive” when combined with the integration of these tools.
I do TDD – red/green/refactor. I have Git pre-commit hooks, triggers to run tests locally, Bash aliases to automate frequently-used Git commands and sequences etc. I am a unit-testing evangelist. I have tests for all sorts of things. And when working on a feature, I commit early, and I commit often.
(I don’t think I can do every 15 minutes though – maybe one day :-).
But here’s the key point: Because I know I am later going to rewrite the history (using Git Rebase -i), I write “disposable” commit messages, largely just to remind myself where I’m up t0.
Now, finally, when I have my feature ready, I ensure I update any in-code documentation – as you say, documentation that lives in the code is best, and ideally it’s best if a web page can be generated from the code (e.g. YARD in Ruby etc).
Lastly, I squash everything together into a single commit (or sometimes into several commits if there’s a logical reason for it – like I’d keep whitespace fixes etc in a separate commit) – then I push to Bitbucket.
Bitbucket then sees that I have written a properly formatted commit message, and this triggers its auto-formatted pull request. My colleagues are automatically notified, and now we can all review the patches/diffs/PRs in Bitbucket’s nice interface, and we can discuss the code in there.
I always recommend this blog post here on how to write a Git commit message
https://chris.beams.io/posts/git-commit/#seven-rules
Now. Does this seem like a lot of work? At first it does. Sure. It scares most people off, just because it seems like a lot of work.
Actually, it is not. Once all of the Git commands are in muscle-memory, it’s surprisingly fast. I feel that I spend 99% of my time thinking about and writing, refactoring, testing code – and about 1% of the time writing about what I’ve done in commit messages, and doing related Git commands.
The effort spent writing about the code pays off in other ways.
1/ I remember better what I did.
2/ I get better at communicating code ideas in words.
3/ I can always find in the log the details of what I did. So, if I remember solving a problem one way 6 months ago, I just find it in the log to remind myself. But it’s pretty hard to find in the absence of a well-managed log.
But of course the primary benefit of all this is the power it adds to:
– git show
– git show –stat
– git blame
– git log -p
etc
To me, git show is the single most useful piece of documentation that can ever exist — but if and only if there is team willing to squash their commits.
But even if I can’t always get others to co-operate, it’s worth it just for my own work.
I would make one comment on your idea about linking to external comments in Jira via the JIRA story ID.
This, to me, is a violation of the idea that the Code-is-the-Documentation.
Yes, it’s kind of okay if the documentation is found externally in Jira. But what happens if that Jira is taken off line? What if there’s no network connection? Etc.
It’s just so much better and more natural and more consistent with Code-is-the-documentation — to me — to have all of this documentation in the actual Git log.
I hope this is interesting!
Hi Alex!
I’m somewhat unclear on your use of GitLog as an example of “Code is the (comprehensive) documentation” …
– I think commit-messages and git log/show are contained in the CVS repository, not in the actual source file itself (such as JavaDoc).
– Martin’s “Code is Documentation” clearly states he doesnt mean it is *the*/all/only documentation, only that it is a form of documentation. This refers back to Jack Reeves ’95 article that “the source code is the design”.
– Commit messages usually try to (very briefly) identify purpose and rationale of a change (which is a different kind of documentation than design). This is also what request/defect/change/issue-tracking tools (like JIRA) do, only more comprehensively.
– Aside from code itself being a form of documentation, there is another key principle at play here that relates to “locality of reference” between a thing (code, executable, test) and the description/explanation of the “thing”, which I call “Locality of Reference Documentation” (or, the LoRD principle, see http://wiki.c2.com/?LocalityOfReferenceDocumentation (this is from 1997 — it was also one of the key tenets behind the design of Doxygen back in the day)
– What you are doing with Git Logs is a form of change identification+documentation, and more an example of LoRD than of “code is documentation”. Physical closeness of storage/archival (the commit, and the description of its meaning/purpose) can be one way to achieve this, they key point here is the “cognitive distance” (e.g., visual closeness) more than the physical storage proximity.
That said, I would prefer if the same tool/repo/db served the needs of both version-control *and* tracking (and project-wiki) for that matter — properly distributed (the same way Git is a DVCS), but realistically few tools do that.
Concerns about one tool being disconnected/out/offline from the other is certainly real, but not all that durable or overarching. (It happens from time-to-time, doesnt tend to last for long, and isnt sufficient reason to not make ample use of it, especially since access to the change rationale/description is typically not a “critical blocker”). Otherwise it wouldnt make sense to use it all that much in the first place.
Comprehensive verbose documentation of a logical/conceptual change stored across multiple commits doesnt create a sufficiently comprehendible narrative. There is physical (and temporal) cohesion between each commit and its “message” but it severely lacks “coherence” across all the microcommits of a single logical change.
Better to have a different form/format for telling the broader story. It can be a tracking-tool (such as JIRA), but doesnt have to be. But I would still expect a link/reference between the commit/message and its corresponding JIRA issue.
Ive seen this done in a wiki as well, including for user/requirements documentation, as well as design/change rationale (with appropriate linkages) – and its not too much effort to weave it into the CI/CD pipeline so that a “build” doesnt just build the executables, but also corresponding docs/specs/reports in a more cosumer digestible fashion (which can then be stored, even versioned either in the appropriate place in version-control, whither it be with the source, or with binaries).
Ive even seen folks do this with a ChangeLog file (possibly in markdown format) in the codebase itself. So for a given version/commit of the code, the ChangeLog corresponds to that particular logical change so far, but as part of integrating it to main-trunk, some scripting in the automation pipeline distributes/integrates/weaves it all together into the right place in the right order/structure (which could be within a wiki, or an artifact repository, or in JIRA, or the result of a report/query, or even elsewhere in the codebase)
Hi Brad,
I am reading the very interesting LoRD doc you linked, and I can actually see myself reading and sharing that many times! Thanks. No disagreements there.
I would quickly note, though, that the most important reason, in my view, for squashing commits is the power/value-add to commands like –
– git show
– git show –stat
– git blame
– git log -p
etc
If (and only if) the entire feature is squashed into a logical unit, along with its passing tests, README updates, JavaDoc etc, then (and only then) can Git Show etc provide one single view of all that went into that feature.
It’s incredibly useful.
Correct me if I’m wrong, but I don’t believe this information can ever easily be recovered unless commits are squashed, as I (and many others) recommend.
It’s spelled out in more detail in the Chris Beam post I linked above.
“We NEVER intentionally commit a change that we know doesn’t work.” The newbie in me said, well duh?! Guess I’ve gone down the rabbit hole…
Hi Dave,
Please don’t apologise ; on reading the above, I clearly need to try harder to scrub the frustration from my tone. I am better at Markdown files and Commit Messages than Blog Comments! Sorry. Also, I am quite a bit older than my 10-year-old WordPress Avatar suggests (if only I could figure out how to change it).
I agree with you completely about Code-as-Documentation, and I also understand the Async Manifesto to be in agreement with you on this more limited point. I definitely agree that your code example 3 is best.
I would say, though, that as the hypothetical maintainer of this code base, too many comments is a big problem if and only if they serve to explain otherwise-unintelligible code. If I don’t like the comments, I can remove the lot of them in seconds with one Perl one-liner + git add -p (to preserve the remainder that are useful).
But this is true in only one direction. If, on the other hand, I inherit a code base that is both undocumented and unintelligible, I have a much, much, much bigger problem. So: I tell people when in doubt to comment ; if they don’t know when to comment, they should comment ; I can refactor any unhelpful comments later.
I think it is also not hard to learn how to write good comments–but: it is much harder if young devs are being told instead on Twitter by thought leaders of the Agile movement to “Zero Comment” their code (a true story; I saw this recently).
So, these are Dangerous Ideas.
In the hands of master programmers, I assume that they do lead to better codebases. I’m but a Grasshopper, so I take your word for it. But in the hands of novices, they can lead to disaster.
Thus, I don’t doubt it when you say, “The best code-bases that I have ever seen tend to have less, rather than more, documentation”, but there are also spurious correlations that can confirm one’s ideas. My initial guess would be that, more often than not, the lack of comments didn’t cause code bases to be good ; rather, I would expect that a state of being good caused them to lack comments.
Yes, look, I enjoyed the analogy of the antisepsis in surgery, and I genuinely look forward to a blog post on it, if you write one ; but it has made it even clearer to me, that yes, you really are saying, “No Matter What Else”, “Thou Shalt Not Branch”. Just as there is never an excuse for a surgeon not to wash their hands before surgery, there is no excuse to create short-lived feature branches.
This is extreme.
Where you write,
“If developers leave the company, the rest of the team brings new people up to speed, and works in a way to limit the risk of only one person knowing anything (back to pair-programming again, amongst other techniques).”
I agree that this is (one) valid solution to the easier problem of developers leaving a team, but it ignores the harder problems.
1/ What if the entire team is made redundant and the code is handed to a new one, in a new company?
2/ What if Silicon Valley poaches all the good developers in a team, and leaves behind only the ones who were struggling?
3/ What of remote engineers, like in my team, in different countries and different timezones?
The value of tribal knowledge is no value at all and in fact a curse in all of these scenarios. In (3), tribal knowledge either doesn’t exist at all, or exists in pockets, because it can’t be transmitted long-distances ; and in (1) and (2), all the tribal knowledge disappears completely as it walks out the door.
I should add that I don’t like Pair Programming, and regardless of–and perhaps in part because of–my own feelings towards it, I don’t predict it will ever be mainstream. I simply don’t like it ; I don’t enjoy it. I don’t like being locked in a 9-5 schedule ; I don’t like being unable to get up and go for a walk without impacting my colleague’s productivity ; and perhaps more importantly, it feels all too much like an Arranged Marriage to me! I don’t want to be forced into a very close relationship with someone, just to write some code. It’s unnatural. That’s me.
But does it work? Sure. I think so. I just don’t like it.
My dream job is me sitting at Manly Beach (in Sydney) at odd hours armed with a shiny MacBook Pro, sunglasses and other essential gadgets–and loads of coffee!
Can we at least agree, in the interests of being scientific and transparent, that you should document up front all of the dependencies and other assumptions in the Don’t Branch! method. People deserve to see it written out clearly in black and white that, if they are thinking of adopting this method, they must also be planning Pair Programming and related practices that will obviate the need for Code Review.
If I introduced this method in my team at the moment, it would be the beginning of the end. No doubt about it. We would end up being hacked and the company would die. But hey, I still have to figure out a way to remove a problematic long-lived develop (integration) branch before I’ll ever have to worry about it.
On commit messages, you have said that you,
“…treat commit comments as important things. I diligently comment on every commit, even when working alone, and will often pause to think of a meaningful description of the change. I find them useful, but their use is orthogonal to understanding the code. They tell a different kind of story. They may let me hone in on a particular change, but I don’t expect them to explain that change, merely highlight that it exists and provide some navigational guidance through the information space of the code base.”
So, do you agree:
1/ that, while you may do this (and is it more more of an old habit, or do you still strongly believe in its value?), it is a fair criticism to predict that that no one else following your method will bother? Because I can say, without the slightest exaggeration, that I have never, once met a developer who promoted faster-than-light interpretations of Agile who didn’t write gibberish in the change log as a badge of honour.
2/ a hypothetical change log with commits squashed as features + documentation–my way–would have far more value, that is not necessarily orthogonal to understanding the code, than commits in your own system, which can only provide, in your words, “some navigational guidance”?
Finally, I wish to note the implication of what you reveal here –
“As a consultant I rarely see code that looks like 3, [and] most code I see looks like 2. It is documented, [but] the docs don’t really help, and in real world systems of more complexity than this, the docs are usually wrong – they have drifted out of touch with the code.”
See, I was a system administrator, and only in the last 10 years did I learn the fine art of programming. And in my space, as a Cloud Developer, this – https://perl.plover.com/obfuscated/ – is often my reality, not a joke. I would be so happy if I could expect to walk into my next gig and find (2). Instead, what I find is layer upon layer of undocumented hacks–and no clues left behind as to why these hacks were applied, when in fact for the cost to their authors of 1 minute of commenting, and 30 seconds of effort in the change log, my team would now be at least twice as productive as it is.
Is it possible that, actually, as a famous computer programmed, you really do get hired only by the best of the best, and you rarely have to see what the rest of us have to deal with? Oh my gosh, how I wish I could inherit some code written by Donald Knuth!
I’m in the process of trying to introduce source control into a Data Warehouse, and with it a deployment pipeline. There is very little published on how to do this but loads on why I should do it.
Take it as read that I’m sold on the why. I thought I had got something that could work until I read this article.
Has anyone got any guidance on how to achieve this particularly in the context of large (multi terabyte) DBs.
I have done some work on this kind of thing. If you haven’t seen it already, there is a very good book called “Refactoring Databases”.
When you start getting to large data-stores, you need to be flexible in approach, I think. Some stuff you can do at deployment-time (a batch process really) others you need to build into the app to do run-time migration.
The deploy-time stuff is really about making additive changes and tracking each as a set of deltas which can be versioned and then played. There is a tool called FlywayDB that might help. Redgate also do some commercial tools that may help.
The runtime stuff is a bit of a maintenance overhead, but is really the only way to cope with genuinely huge data-sets. Build the ability of the application to handle old versions of the system and represent them in a consistent way. Essentially you manage an ever-increasing collection of adaptors (or mappers) from every-old-version to current. This is greatly helped if your Continuous Delivery practices are in good shape. It allows you to change code with more confidence, and so helps you to be able to maintain the collection of mappers.
Pingback: Oprzyj się o gałąź główną
Pingback: CI and the Change Log | Dave Farley's Weblog
Pingback: Perceived Barriers to Trunk Based Development | Dave Farley's Weblog
Pingback: (Un)regelmäßige Integration: Stolpersteine für Continuous Integration
I stumbled over this article and finally realized that I am not alone in this battle. I try to push my team on daily basis to use CI, TDD, SOLID, etc. and they reject them without even having ever tried them. They believe that just by using SCRUM will make their work agile.
Thanks for sharing this. Branching is for people who don’t like to code as a team and to profit from others feedbacks. They like to live alone in their islands without being disturbed. They are not able to break down their work in small testable units and to merge. After so many years of development for agile methodologies people did not evolve and still stick to old fashion techniques and to legacy code. And I don’t want even touch the field of data science where they just create legacy scripts. That’s so disappointing.
I’m an Agile XP Software Engineer / Software Architect / Manager with more than 30 years experience working across different industries.
In theory you idea sounds feasible, but in practise it’s not. Based on my experience I can say that your idea is flawed because it focuses only on Processes, but ignores another 2 important pillars of Agile and XP: People and Projects.
I guess that we will have to disagree about that 🙂
I think that this is, in some detail, about the importance of the human process. Speak to some of the signatories of the Agile manifesto, who coined “People over Process” and they will say the same thing as me, only in different words.
Here is one example from Martin Fowler, “It is these problems that CI was designed to solve”, https://www.martinfowler.com/bliki/FeatureBranch.html
I find it ironic that someone claims to be an XP practitioner would be here touting feature branches. The feature branch is antithetical to XP and agile.
If your experience suggests that feature branches are a better strategy than TBD then I would suggest that you broaden your experience: Google, Amazon, Netflix, and many others disprove your claim that TBD does not work in practice… in spades.
Some of THE most successful software teams current have tremendous success over teams using feature branches. There are many many reports out there to show that TBD teams produce better results, consistently better results.
I would suggest you broaden your experience if it shows feature branches to be more effective.
Pingback: How Armory and Spinnaker support high performing teams (Part 1) - Armory
Pingback: Trunk-based Branching Modell – Fundament für DevOps Teams – Nordhof Service GmbH
Pingback: Trunk Based Development & Healthy Branching Model – IT – Agile & Clean Code
You frankly have no idea how it really is and why CI is terrible for effective, sustainable, and simple codebases.
I’m not some old guy thinking back to how things used to be and wanting to keep the status quo, I have “only” been in the industry for 5 years and it has always been feature branches.
I can only think that someone would prefer CI if they were:
• Working on a solo project, if something goes wrong you are to blame and are the only victim, you also only work on a single scope at a time so there’s less chance of conflicts. I personally still use feature branches for personal projects because I do have ADD and I hop around a bit and the organisation is fantastic and there are never merge conflicts.
• The project is tiny, there’s literally nothing to the codebase and it’s similar to a solo project with only 1 or 2 people touching it.
• You have not experienced effective feature branches, you have only experienced groups that lack communication which makes not having branches live too long worse than having cowboy coders screwing things up.
• You are unable to communicate and plan across teams, feature branches do require coordination which some cannot be bothered to do.
CI is completely unsustainable, similar to monolithic coding (which I’m aware you are a fan of), you just have too much going on at once. You might think having a dozen branches is too much, but you’d be wrong there’s far less to account for.
Can feature branches get out of hand? Yes but only when there is a break down in communication and planning. While with CI you have a massive amount of feature flags to clear up and having to deal with experimental code changing and potentially being inoperable for some time which can have problems downstream.
Code quality is something that CI does not allow for, it pressures teams to get their code working ASAP, no code review, often not refactored, implementations may leave in the feature flags. Feature branches aren’t even slower despite having more time to work on your code and refactor it ready for review and get many eyes on your branch to find problems but also requesting more features. These extra features are usually added at the beginning, but if right at the end another branch is made and anyone who wants the working refactored feature can merge with it and use it to later get access to the other branch. No worse than CI, while better.
With feature branches completely avoid cowboy coders who do what they want and don’t care about quality or testing because they’re awesome and flawless and their mistakes might not get picked up on for years because only they have actually read it. Feature branch there’s a much smaller section of code and you know that that is everything that has been added, changed, or deleted you don’t have to go through potentially hundreds of commits to find everything that has been added, changed, or deleted.
A mythical problem CI advocates spout about are feature branches that go nowhere and live for years and projects can have hundreds of these dead branches. The solution, there’s planning of the scope of the feature written out clearly and specced, and there are chains of dependencies so the team working on the feature know what needs it and what timeframe they need to be up. Some feature branches are experimental and they may never be merged but it’s known going in that it may never be merged and it can be culled.
Teams are good at getting feature branches done and rebasing codebases periodically at planned times.
I have been fortunate to not have to work on any CI codebases, I have friends who have to work in them because of management and it sounds like hell and a lot have quit specifically because of CI. CI treats programmers like worthless code monkeys, “just get it done, I don’t care how you do it, but you need to do it fast because everyone wants to use what you’re working on while you work on it”.
I have however had to work on codebases that used to be CI and have to clean it up and both times they have been a complete mess that for the first after cleaning it up to add more features we didn’t have a roadmap and despite being cleaned it was not going to be anything more positive than hell modifying it, so we recreated the codebase with feature branches and everything mapped out and the result was much easier for future maintainers to understand what has gone on. With CI every feature is a splattering of changes all over the place, but with feature branches, the feature is altogether. The second it didn’t need a full rebuild but it needed massive restructuring and refactoring massively inefficient, but working, code.
Feature flags are terrible, the CI mentality is that “it’s good to have access to features right now and we can build on top without delay” however that is not a sustainable way to program. You use feature flags knowing that it may break, but you’re just accepting that your code will then break and I guess you value your code as being worthless but you’re better off using your time working on what you’re meant to be working on and get to use that feature once it’s finished, refactored, reviewed, tested experimentally, and merged. If you NEED to access the feature now, you can just create branches and merge them and use it there in its own branch ready to go, not live and shouldn’t be live.
Feature flags just create spaghetti code and also potentially large areas of dead code that isn’t used anymore. In both projects, I’ve had to remake or restructure both had vast nets of obsolete code left in because nobody took it as their responsibility to clean it because they just commit to main “every 15 minutes” and they’re doing their job. Feature branches have the responsibility to clear out obsolete code and because it’s all at the same time they can make an instantaneous swap. Afterwards, anyone who branched from that feature can test their code, refactor, review etc.
I came across your YouTube video spouting out about CI nonsense and I find that it is very dangerous and damaging to be teaching beginners that they should use CI. You are leading programmers down a deep dark hole and if they get a job they have to do a 180 and do feature branches because they work better, or they’re that idiot who keeps pushing to main and ends up being shouted at for repeatedly doing that and they might cry and they have a bad experience working as a programmer; or they find a job with a CI codebase and they simply don’t know that there is a better experience out there you just have to deal with planning, communication, and more git commands.
There are no downsides to feature branches compared to CI – you can do feature branches with the same mentality as CI and do CI better, but it is better to fully embrace feature branches and make everyone working on it much happier. I am glad that CI is heading towards a dead branch of its own despite your attempt to try and make it live longer, and programmers know that they can quit and find another job and not have to deal with it.
Dear Skye,
How you can start a post with
> You frankly have no idea how it really is and why CI is terrible for effective, sustainable, and simple codebases.
and then a few paragraphs down say
> I have been fortunate to not have to work on any CI codebases
…
I honestly can’t even.
Pingback: DevOps Reading List | Message Consulting
What are your thoughts on feature branching in an environment where every feature branch gets its own dedicated CI agent that builds the feature branch code and runs the tests?
This is where I find myself in my latest position. The issue I have with this approach is how long each branch lives (typically multiple months) before a pull request (PR) back to master. And there tends to be a (often painful) merge from master back to the branch before the PR get announced. The result tends to be diffs with ridiculous numbers of changes that are not related to the feature/fix being worked on. Frankly, it makes me want to quit. It all seems so very, very messy.
The problem is that the the version that exists on each feature branch is the reality of the system, the interesting version is the combination of all the versions on all the feature branches, that is what Continuous Integration is designed to evaluate. In the model you describe, however frequently people pull from trunk to their FB, they are not seeing the changes in other people’s FBs, so this is almost certainly not a version of the software that will ever end up in production, so you are testing the wrong version of the code.
The data (from the State of DevOps report, and the DevOps handbook) says that teams that use FBs produce lower quality software more slowly than teams that practice true CI where “everyone merges their changes at least once per day”.
Thanks for that Dave. My latest gig is quite a surprise of tech mix. They appear to love pull requests and feature branches but there is still merge hell with fixes on one branch breaking stuff on another.