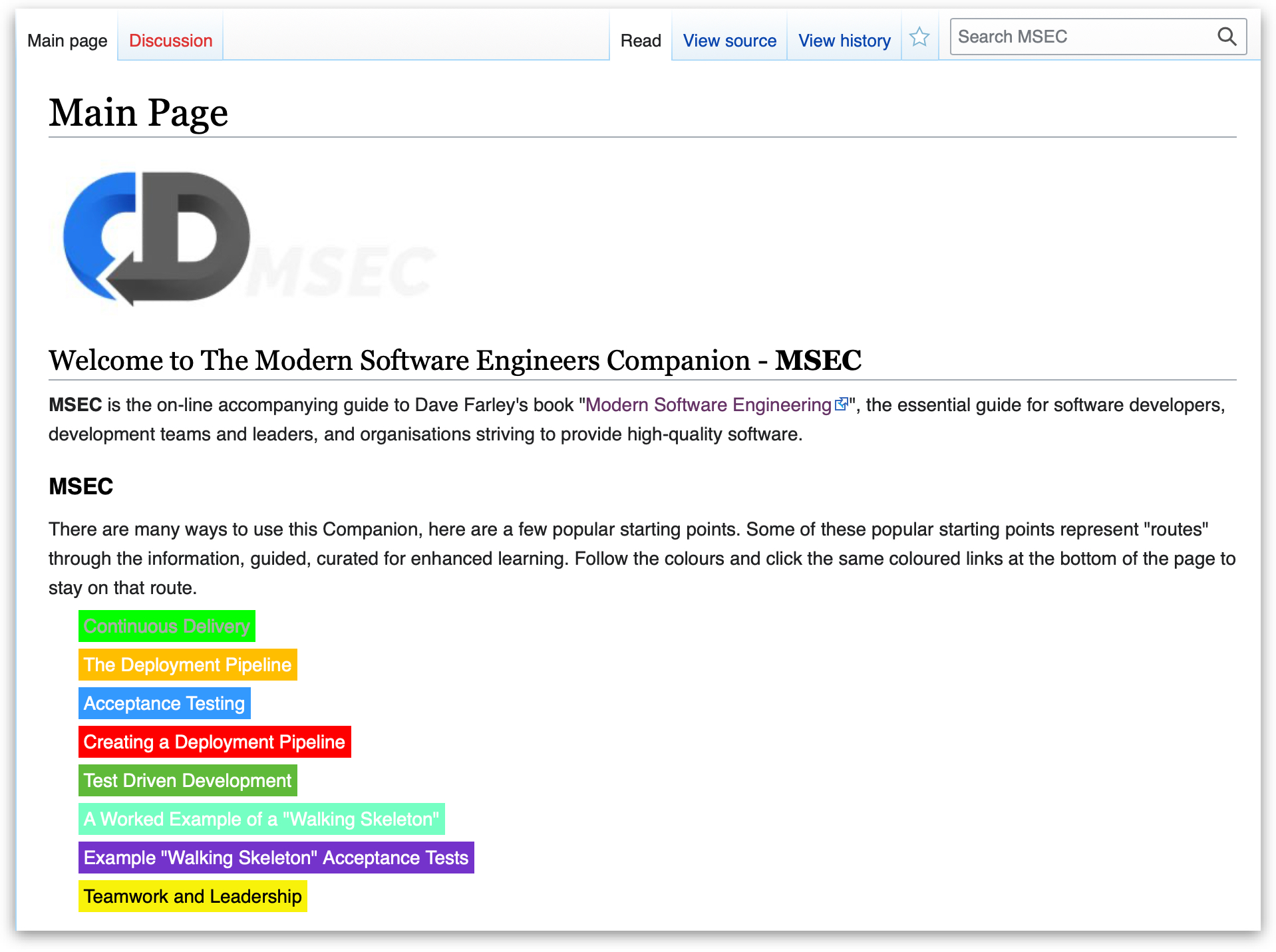
I have been working on a side project over the past year or so. I had been making content for my YouTube channel and publishing articles, how to guides and other writing and learning from others, but lots of people were asking for a more guided experience.
So I started to think about what that would be like. I have created a wiki containing lots of descriptions and information, but also lots of links to my, and other people’s content. I am quite excited at the prospect of this. It is a kind of curated guide to what I think works in software development, but it also has that nice wiki feature of being able to go directly to the stuff that interests you, and to explore random, side-paths, as they pique your interest.
The idea of MSEC is to make useful, valuable information available to people, and to coordinate useful, guided paths through the information.
Our plan is to grow this significantly over the coming months and years. Currently we have paths on a variety of topics.
The colour-coded headings represent guided paths through the information. If you are interested in Continuous Delivery, or Acceptance Testing or Teamwork and Leadership, you can follow the colour-coded track.
Many of the pages have links out to relevant videos from my YouTube channel, relevant articles on the topic, from me and other people and in general pull together what is hopefully a lot of useful, tutorials, how-to-guides and reference material.
The idea of MSEC is for this to become a growing, organic resource that can help to guide people’s learning and to find useful answers to problems.
Our goal for MSEC at Continuous Delivery Ltd is to build a useful guide and reference, that will help people in their work. Pulling together descriptions of good practices on a wide variety of topics that can help people and teams to do a better job.
If you’d like to take a look and explore, there is a demo version of the MSEC to explore…
We are currently making MSEC available to our Patreon members, so if you find the concept interesting and would like to check it out sign-up and take a look here:
The usual route to a Technical Leadership role is by getting promoted because of your technical skills or experience after working on a successful project. That was certainly true of me: I got my first Technical Leader role in a startup, working on what we’d call these days a platform team.
But managing people is VERY different from programming computers! So this is rather like being dumped in the deep-end of the pool. New Technical Leaders have to quickly learn some management skills, on the job, probably with no training other than their previous experiences of see the impact that their technical leaders had for good and bad.
This is a big step, and may be one of the most difficult changes that we make in our careers, and let’s be clear, this isn’t about just us any more. Now our choices will influence other people and their work. So how can make a good job of this? With the benefit of about 35 year of hindsight, on reflection, there are a few things that I wish I had understood better and learned more quickly back in the day.
Help the Team be the Best they Can Be
As Team Leader, it’s no longer about having the best technical skills yourself, but getting the best out of the team as a whole.
This means allowing people to find their own solutions, work and learn in their own way, and make their own mistakes. This might be one of the most difficult things to learn as a new team lead – allowing people to do things differently to you; maybe even not as good as you can do it, is or at least should be part of your job now.
The desire to make the best software and lead a successful project tempts us to control and drive the work: to micro-manage the team. But by making all the decisions, and giving detailed instructions, or ‘programming by remote control’ the Team Leader will become a bottle-neck, slowing the team down, and demotivating people: and the performance of the team will be worse not better.
I think that there is a good analogy with sports teams here. The manager of a great football club isn’t the best footballer. They have a different role. They may hire team members who are much more skilled than they are, and then help them to become even better. Or they may take a young player and coach them in specific skills and later help them to become as good as they can be.They may suggest tactics and the approach to a game, all of this is in service to the team as a whole.
The job of a leader is to amplify the effectiveness of the team, not to make all the decisions themselves.
By focusing on the overall goal, and taking a step back, I think that the job of a Team Leader is to allow, and encourage, team members to learn and grow. Your job is to support them, maybe through coaching, but certainly by providing more opportunities, and sometimes guidance, that allows them to develop their skills and be proud of their achievements.
Use the Position to Remove Barriers
A new Technical Leader has access to more resources and whatever the size of the team they lead, they have more influence, and greater access to other influencers in their organisation than they did before. They should us this to support their team: building relationships with other teams; removing barriers; shielding their team from the impact of outside interference; and, finding ways to keep the ‘admin’ stuff to a minimum.
This isn’t about keeping people in the dark though, it’s important to keep the team informed about what is going on elsewhere, and I like to encourage my team to communicate with others about their work and achievements – maybe via a blog, or presenting at team meetings. Maybe even encouraging people to spread their wings at speak externally at conferences and meet-up groups.
Use Your Skills and Experience when it Matters
It’s not the role of Team Leader to have all the answers, make all the technical decisions, or to be the best programmer; but neither should you leave all that behind you and become just a ‘manager’.
I draw on my experience of the technical and organisational aspects of software projects to set reasonable goals, achievable expectations, and minimum quality standards, and then encourage team members to try their own ideas, and use their skills to meet these in different ways.
I try and resist the temptation to dive in with solutions too early, but can offer suggestions when the team is stuck, or can’t reach a consensus.
Be Prepared for Difficult Conversations
Feedback is really important, and not just at Performance Review time. Both positive and negative feedback are important and both can be difficult/embarrassing at first. I try to find ways to regularly tell people when they have done well, learned something new, and contributed to team achievements. I have also learned that it is important to intervene early, before minor niggles escalate into major problems, by having a private word with someone who may need to do things differently.
If you ever need to have the most difficult conversation, about unacceptable performance, or even dismissal, do not spend time sharing how tough you have found it – its always worse for them!! Give clear, objective information, give them time to reflect on what you’ve said, and offer sources of support (not necessarily from you).
Like it or Not, You’re Now a Role Model
As Team Leader, people will look at what you say and do, take more notice of your ideas, interpret your suggestions as decisions, and judge you, or copy you. I wish I had appreciated this more, and spent more time thinking about the sort of leader I wanted to be, and made more effort managing my performance accordingly.
This is not about being aloof or commanding, you are member of the team and have some different responsibilities. That doesn’t mean that you deserve being a role model, but you are. So you need to be consistent, and fair, and follow your own rules.
I had a great boss early in my career, who was a lot of fun to work with, we laughed a lot, and messed around, but also we knew when he was telling us what we needed to do. I learned a lot from him, and as a team we trusted him and, I hope, supported him in return.
Perhaps the most important role of the Team Leader is to create a learning culture and a safe environment in which colleagues can share ideas, and make mistakes.
We have just released a new learning track on our “Modern Software Engineer’s Companion” (MSEC) on the topic of “Teamwork & Leadership“. This is available to Patreon members, find out more here: https://www.patreon.com/continuousdelivery
In many organisations where high-quality software development is essential for success, there is often a bias toward “immediate technological solutions” (automation, development tools, language adoption etc.). These things matter, but they aren’t the most important part. Often, less attention is paid to the culture and organisation of the groups of people who do the work. For success we need excellence in technology, sure, but we also need excellence in culture and organisation.
It adds something important to our discipline: it defines an approach to using organisational structure as a tool to achieve better results in software.
“Team Topologies” is an excellent guide to structuring and keeping teams, processes and technologies aligned, for all kinds of organisations. It gives us a vocabulary and a model to direct our thinking in a way that allows for scaling up, and helps us to organise teams for effective software development. I think this is one of those “must read” books for anyone serious about professional software development!
The authors start by tying down some important assumptions, and establishing some key ideas and terms used throughout the book:
‘An organisation is a sociotechnical system or ecosystem that is shaped by the interaction of individuals and the teams within it.’ (my emphasis)
‘An organisation is the interaction between people and technology.’
‘… “the team” is something that behaves differently from a mere collection of individuals, and […] the team should benurtured and supported in its evolution and operation.’ (my emphasis)
– “Team Topologies”
So what are some of the key elements that we should consider as essential to an effective team topology?
Team Size
It is very well established that small teams are vital to doing a good job in software development.
Fred Brooks said it in the 1970s, Kent Beck said it again in the 1990s and lots of people have repeated it in different forms ever since but still not every organisation listens!
The researchers then measured how long it took each group to generate 100,000 lines of code.
The researchers’ findings were quite remarkable:
On average, for all of the teams, it took nine months to generate 100,000 lines of code.
On average, the teams of 20 people beat the teams of 5 to a 100,000 lines but they only beat them by a week over that same period of nine months.
Conclusion 1: a team of five is nearly four times as productive as a team of 20.
The study then looked at the quality of the code measured by the amount of defects:
On average, a team of 20 people produced five times as many defects as a team of five.
Conclusion 2: a team of five introduces fewer defects than a team of 20.
Small teams are more productive and produce work of higher quality.
Cognitive Load
Matt and Manuel have an explanation for these findings. As the complexity of a system increases, so do the cognitive demands on the team that is responsible for building it. This cognitive load is the amount of stuff that we need to think about to do our work: as team size goes up, complexity increases and so cognitive load goes up accordingly.
If a team’s cognitive load exceeds what it can cope with, this will result in a delivery bottleneck, causing delays, defects, poor quality and, unsurprisingly, a lack of motivation from members of the team
“We need to put the team first, advocating for restricting their cognitive loads.” – Team Topologies
Keep Your Friends Close
Working in small teams isn’t principally about writing software – it is about humans. The Dunbar Number – around 150 – is a limit on the number of stable social relationships that humans can maintain. When we try to grow an organisation – such as a company – beyond this number of people we tend to experience a huge jump in complexity.
There are other numbers that seem to be common for effective human cooperation: five people is about the limit for close personal friendship, 15 people is the limit for how many
people can share deep trust and about and around 50 people for mutual trust.
So if we want teams to be efficient and effective, they must be small and we need to take these numbers seriously. Matt and Manuel suggest that a team should consist of five to nine people, or if you favour pairing, like I do, then select an even number between four to eight.
If a team gets bigger than this you should be looking for how to split it into two (or more!) teams.
Team is Primary Unit of Work
The smallest unit of software ownership isn’t the individual, it’s the *team*. Therefore your prime directive as a manager is to craft and tend a healthy, high-functioning team.
Even when this leads to outcomes that are less than ideal for individuals.
The team, not the individual – no matter how talented and smart they may think they are – is considered the primary unit of work.
The team ownsresponsibility and works as a unit to achieve shared agreed goals this gets us to the next vital aspect of a team-based type of organisational strategy.
Conway’s Law
“Any organisation that designs a system (defined broadly) will produce a design whose structure is a copy of the organisation’s communication structure.”[2][3] — Melvin E. Conway
Something that we often don’t consider, is that the human structures that we build in organisations are information systems too – remember the three assumptions of Team Topologies listed above?
How we structure our teams and organise our work is deeply related to how we are able to structure the code and systems that we build.
This is quite remarkable when we stop to think about it: Despite decades of management culture, the best that we can do is design systems that reflect the company org chart – in code!
Yet it goes even deeper than that. In information terms, this all comes down to coupling. The communication structure in an organisation implicitly defines how much or how little teams are coupled to one another.
For example, if team A needs to communicate with team B and team C to get work done that’s going to have a very different outcome to team A being able to make progress alone and in parallel with the others.
To enable that less constrained approach, we need to set the boundaries and responsibilities for the teams in a way that prefers teams that are loosely coupled with respect to other teams.
To do this we must organise in ways that allow teams more autonomy.
To achieve this autonomy, we must divide work in ways that minimises dependencies between the teams, a kind of team first approach to design.
We aim to organise the boundaries between teams so that they are loosely coupled enough that teams can make progress independently – even when they’re working on things that span teams.
One recommended strategy is dividing teams into what I used to call functional teams as the primary focus.
Aligning teams with a bounded context in a problem domain is often a good starting point for this since these boundaries usually mean that the problem is naturally more decoupled at these points.
Stream Aligned Teams
The “Team Topologies” authors have a different name, and a richer model, for these functional teams – they call them stream aligned teams.
A stream in this context is a continuous flow of work aligned to a business domain or organisational goal.
A stream aligned team is aligned with a single, valuable, stream of work.
The goal in terms of structure is to identify decoupled stream aligned teams, and then support them to work independently.
In high-functioning organisations Matt & Manuel say that you’d expect that the ratio between non-stream aligned teams and stream aligned teams to be probably one in six or one in ten so that most teams are focused on the stuff that really matters to the organisation.
Mama We’re All Agile Now…
When asked, many modern organisations would characterise themselves as taking an agile approach to their processes. Yet one of the anti-patterns that I see all the time in these self-described “agile” companies is a lack of team autonomy!
The State of Devops Report has long pointed out that one of the strongest predictors of success for a team is its ability to make decisions and progress without needing to coordinate or ask permission from people outside the team.
That’s a lot of responsibilities for a small team but that is what it takes to achieve autonomy in teams – and autonomy and teams predicts that they will build better software faster.
Handoffs
A stream aligned team has minimal – ideally zero – handoffs of work to other teams
This doesn’t only mean that you aim to limit work to reduce handoffs like “we’ve finished the backend services so now you can build the front-end ui”.
It also means that we don’t hand off responsibility to architecture upstream or to testing and release downstream.
All of these things are part of the responsibility of a stream aligned team.
Other Types of Teams
Other types of teams focus on reducing the cognitive load in stream aligned teams. That is, taking responsibility for some other parts of the problem so that stream
aligned teams can really be really productive. In Team Topology vocabulary there are three other types of team, they are:
Enabling Teams
Complicated Subsystem Teams
Platform Teams
The goal of these teams is to support the stream aligned teams.
Enabling teams may lend expertise to stream aligned teams, for example. Given that design and architecture, and ux are stream aligned responsibilities, it’s not reasonable to expect every team to have equal, deep expertise in these areas.
The goal in a well-designed organisation is to nurture the capability where it matters, and that is in stream aligned teams. Aim for every team to have the skills that it needs to make progress most of the time, and enough knowledge, enough understanding, to recognise when something is outside their experience. At that point they can call for help from an enabling team.
Enabling Teams
“…an enabling team’s job is to help stream aligned teams with acquiring missing capabilities” – Team Topologies
The enabling team may lend the stream aligned team an expert for a short while to help them with a problem, or steer them in the direction of learning or resources that may help. The expert’s job is not only to help solve the stream-aligned team’s problem, but also to help to use fixing the problem as a chance to teach the borrowing team a little more about their area of expertise in that context.
Enabling teams can provide a vital role in helping organisations make the transition to more effective development practices.
Big organisations making the transition to continuous delivery often have strong enabling teams. These teams are focused on learning, and spreading, the skills and techniques of continuous delivery. These people typically start off building the pipelines and optimising build systems. These teams can have an enormous impact on moving the dial in an organisation.
Complicated Subsystem Teams
The focus of complicated subsystem teams is to reduce the cognitive load of stream aligned teams by taking responsibility for technically specialised complex parts of the problem. For example, these could be:
writing video codecs
financial trade matching
interfacing with complex hardware
specialised scientific/mathematical algorithms
A complicated subsystem team is characterised by needing people with deep expertise in a relatively narrow field. Their job is to provide code that can be used to deliver the complex value but doesn’t require such deep expertise to use it. This is more than just the idea of component ownership; this is a focus explicitly for complex components with very strong emphasis on hiding that complexity from the stream aligned teams.
Platform Teams
“…the purpose of a platform team is to enable stream aligned teams to deliver work with substantial autonomy” – Team Topologies
If you can’t begin work on a feature until the platform team has delivered some change you aren’t working autonomously.
I have a video on my YouTube channel that explores approaches to design and team focus aimed at platform teams, including technical ways to help achieve this kind of autonomy:
The evolution of the platform product is not simply driven by feature requests from development teams. It is curated and carefully shaped to meet their needs in the long term.
Conclusion
I think that the book, Team Topologies is important, and adds a significant piece to the jigsaw puzzle of how to build great software.
The overall goal is to take autonomy seriously, and structure our organisations and teams so that they can take advantage of it. Teams need to be able to make progress independently of others – that is autonomy!
I really strongly recommend this book to every leader in every development organisation with more than 10 people and probably even to people in organisations with fewer people than that.
I have a new book out. It’s called “Modern Software Engineering” and I have been working on it for the past few years.
The ideas in it grew out of a growing realisation that the way that I approach software development, and the way that all of the teams that I was familiar with, that I considered excellent at software development, shared some fundamental characteristics.
This got me interested in trying to nail down those characteristics and formulate them into a model that I could use to explain what it seemed to me worked best for software development.
Applying Science
I recognised that my own thinking has long been influenced by one of my hobbies, I like to read and learn about science. I am interested not just in the findings of science, but also in the organised approach to knowledge acquisition that it represents. Science is humanity’s best approach to problem solving, so it should certainly be applicable to a difficult, technical discipline like software development.
I had long described my preferred approach to software development, Continuous Delivery, as a simple, pragmatic, application of scientific style reasoning to solving problems in software. This led me to become really interested in exploring this idea in more depth. What does applying an informal approach to scientific learning and discovery mean when we apply it to solving practical problems? There’s a word for that, we call it “Engineering”.
Engineering != Bureaucracy
At this point I got rather nervous. It seems to me that in our discipline of software development the term “engineering” has become either incorrectly loaded with meaning, or emptied of it all together.
On one hand, many people assume that “Engineering” means stifling bureaucracy and heavy-weight process control.
On the other, “Engineering” simply means writing code and nothing else.
Both of these are profoundly wrong. In other disciplines, “Engineering” is simply the stuff that works. It is practical, pragmatic and more, not less, efficient.
Sure, it may offer some guide-rails, constraining our thinking, but it does that in a way that helps us to rule-out, or at least steer us away from, dumb ideas. This is a really good thing!
Avoiding Bad Ideas
In software development we have a poor history of being able to eliminate bad ideas. We tend to make the same mistakes over and over again.
Low-code environments that work on the assumption that you know exactly what you want at the start of a project and that that requirement will never change – good luck with that idea!
So something that was able to steer us away from bad ideas would be a very valuable thing to have.
The Billion Dollar Mistake
The idea that “Engineering == Bureaucracy” is wrong, it comes from a completely incorrect, but understandable, mis-categorisation of what engineering in other disciplines is about, and then applying that mis-categorisation to software.
Humans are used to building physical things, so the production of physical things is front and centre in our minds when we think about making things. The inspiration and design of a physical thing is certainly a challenging problem, but it is so much more difficult to scale that up to produce those things en-mass, that we assume that that is where the only real challenge lies and so we assume that is all that engineering does.
We assume that “Engineering == Production Engineering” and so we, as an industry, made the billion dollar mistake of attempting to improve the efficiency of software development by applying production-line techniques. Didn’t work!
Production is not Our Problem
In software “production” is not our problem! Our product is a sequence of bytes, and we can recreate any sequence of bytes essentially for zero cost.
This means that we NEVER have a production problem! Our problem is always one of learning, discovery and design. Engineering for software then, needs to focus very firmly on that part of the challenge and ignore, or at least automate our production process.
Design Engineering NOT Production Engineering
So how do we optimise for exploration, learning and design?
If we want to look for examples outside of software, this is much more closely related to the innovative creation of new things, than it is to production engineering. Design engineering is a very different discipline. Think NASA designing Mars rovers, or Apple designing the first iPhone or SpaceX designing their Starship.
For this kind of engineering you optimise to be great at learning. Modern engineering consciously designs systems in ways that allow the engineers to iterate quickly and efficiently so that they can learn what works, and what doesn’t. We need to do the same.
Designing Complex Systems
The systems that modern engineers create are increasingly complex and sophisticated, so as well as focusing on learning, modern engineering in general, but certainly modern software engineering, needs to focus us on managing that complexity. We need to focus our tools, techniques and mindset on dealing with the complexity that is always at the root of our discipline.
Software Development as an Engineering Discipline
I came to the view that this assumption that “software development isn’t really engineering” is correct in practice, but very wrong in principle.
How I worked for most of my career certainly did not qualify as engineering, it certainly was closer to craft. However, in the latter part of my career I started to think more consciously about how I could do better.
I started to take a consciously more rational approach to decision making in all aspects of software development. I started to apply some heuristics that would guide me, and the teams that I worked with, more reliably towards better outcomes. It works!
Modern Software Engineering
I have tried to outline this organised, but pragmatic and low-ceremony approach to software development in my new book. To capture some principles that I think are generic to all software development in a way that we can adopt them and use them to steer us in the direction of more successful outcomes.
My thesis is this, if an engineering approach to software development doesn’t help us to create better software faster, then its wrong and doesn’t qualify as “Engineering”.
Like most authors, I was nervous about how these ideas would be received, but “Modern Software Engineering”, my new book, is starting to gather some great reviews and people are finding the ideas in it as helpful as I have. If you read it, I hope that you enjoy it.
March 8th is International Women’s Day, which got me thinking again about why we have so few women programmers (well, in Europe and the USA anyway).
Things didn’t start out this way. Many of the first programmers and pioneers of computing were women. Women like:
Ada Lovelace – who wrote the first algorithm intended to be executed by a computer
Grace Hopper – the first person to design a compiler for a programming language
The history-making Bletchley Park code-breakers.
Katherine Johnson whose contribution to NASA was told in the film “Hidden Figures”
And one of my personal heroes –
Margaret Hamilton who led the team responsible for programming the onboard flight software for the Apollo mission computers and invented the term “Software Engineering”
But, the proportion of women in computing peaked in 1984 and has declined ever since! This is the opposite of the trend in other science, medicine and engineering disciplines. Recent figures I’ve seen, suggest that there may be as few as 15% of people studying computer science subjects, or wanting to work in this field are women and girls. (The gap is worse in Europe and USA, than in India, Malaysia, Africa and China.)
Now I think being a Programmer is a wonderful, challenging, rewarding, rapidly changing, career and I have had the privilege of working with some very talented women. So what is happening in our industry that deters women from joining us?
There are many strongly-held opinions about why this is the case. Misperceptions pervade about what it takes to be a ‘good programmer‘ coupled with a well-established, ‘computer geek stereotype’.
In 2017, James Damore, a senior engineer at Google, was famously fired in response to his memo claiming that there was a ‘biological reason’ for a lack of female computer scientists. Even a cursory reading of science shows that the differences between men and women, whether cultural or biological, are well within the range of variance for either men or women, so James Damore was talking rubbish, from the perspective of the science, and simply voicing his personal prejudice.
I am convinced that what, if any, differences there are are cultural, we have done this. There is a wide-spread ‘toys for boys‘ culture which has developed in our industry over decades which will be very hard to break down.
“Computing is too important to be left to men”
Professor Karen Sparck Jones, pioneering British computer scientist
Is it impossible to change? It’s a difficult problem – but problem-solving is what SW engineering is all about! What can we do more of to provide women with opportunities and to ensure this talent pool isn’t lost to computing? Tackle recruitment practices. Create more positive attitudes to diversity and inclusive organisational culture. Support the work of organisations like “Girls Who Code”. Recognise women role models – women like:
Shafi Goldwasser – the most recent woman winner of the Turing award for her work on cryptography.
…. and, of course, encourage more girls and women to study computer science and learn software engineering.
To mark International Women’s Day, I am offering
50% off any of my Continuous Delivery Training & DevOps Courses
I know that gender isn’t the only Diversity issue that needs to be addressed in computing, and Diversity in all it forms is increasingly important particularly as we are now entering the era of AI, algorithms and machine learning. I wrote more generally on Diversity in computing here. However, this article was inspired by International Womens day and inspirational women in computing.
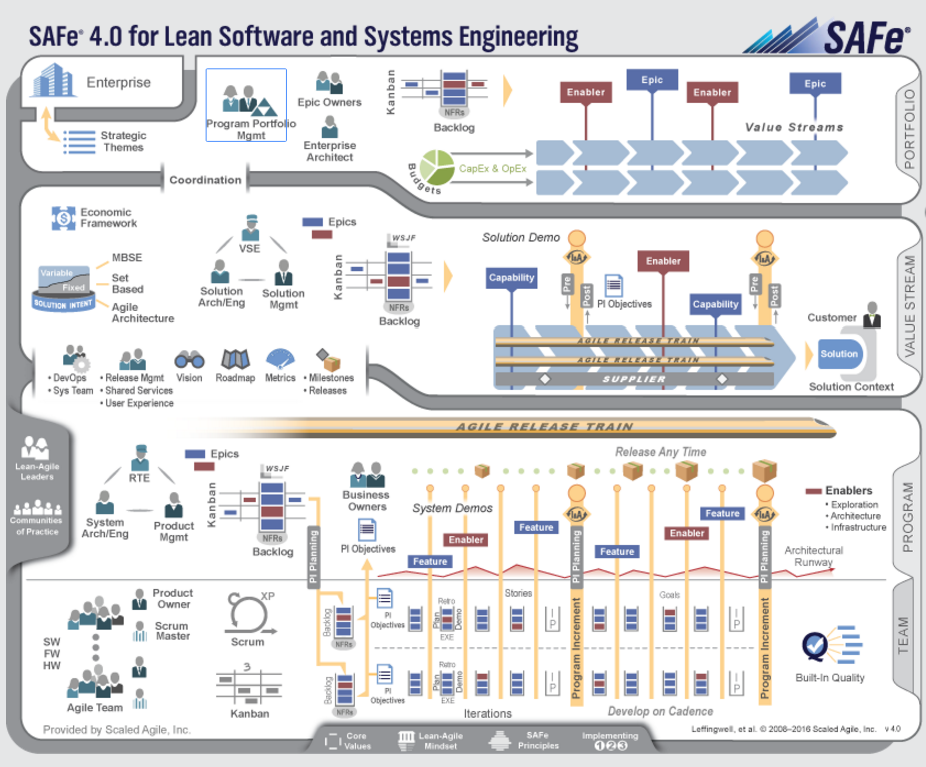
I recently made a passing comment in one of my videos about SAFe, it was a bit of a cheap-shot on my part if I am honest and I got picked-up on it, appropriately, by a viewer.
It is too easy to take cheap-shots at things, so here is my slightly more reasoned explantation of why I am not a fan of SAFe.
My Experience of SAFe
My direct experience of SAFe is limited, but I have worked with several clients that have adopted it as their corporate agile strategy.
The results that I have seen have been in-line with the predictions that I would have made based on my reading of the SAFe approach, and so has tended to reinforce my opinions, and no-doubt, prejudices.
Not Obviously Wrong But…
I have said for years, since I first became aware of SAFe’s existence, that if I look at any small piece of it, while it looks too bureaucratic to me, it is mostly not wrong.
Many people dislike the commercial stuff around SAFe, but for good or ill we live in a capitalist world, so I have no objection to that.
My reticence, and experience, is that I have never seen it work successfully, and I don’t know anyone, anyone that has seen a real successful agile project at least, that claims to.
This is a limited sample of course, and depends on how we measure success, but the orgs that I have seen try SAFe look indistinguishable from the orgs that pay lip-service to Scrum to me. In both cases, they look like waterfall orgs to me.
How Orgs Change
The problem is less a problem of SAFe itself, but more a problem of my perception of how people, and in particular, organisations, adopt change. On the whole they try really hard not to adopt any change at all!
Organisational and cultural inertia is a real problem, and a real barrier to progress. This means that these orgs will read SAFe and then try to force-fit it into their pre-existing mental model. I think that SAFe’s problem is that it looks too much like what went before, therefore fits too neatly into the wrong mental models.
Revenge of the Mutant Methodologies
When I first saw SAFe it reminded me, very strongly, of a previous attempt, RUP (Rational Unified Process). If you looked at RUP from the perspective of small iterative, what these days we’d call, “agile”, teams then RUP made good sense. I was involved in several successful projects based on a very light-weight adoption of RUP. I think that is probably what its creators intended.
The problem was that almost no-one in industry saw it that way. RUP was designed as a kind of self-build-kit for development process, attempting to point (for me strongly) at a more iterative, collaborative (we’d now say “agile”) approach.
What nearly everyone read though was “Ok, so we have to do all this extra paper-work and bureaucracy to do”. One of the first steps in RUP was “select the important artifacts that you will use”, what nearly everyone did was “pick all of the artifacts that RUP ever mentions”. In practice it was often the most bureaucratic version of waterfall that you have ever seen.
The Release Train Plateau
SAFe looks like that to me. There are things that I think are wrong, more complex and wrong, in SAFe.
I dislike the idea of Release Trains, and think that they are an anti-Continuous Integration step, in my experience they often move teams further from where they need to be rather than closer. In some ways you can see Release Trains as a step along the way to Continuous Delivery, in practice they seem to me to, much more commonly, represent a plateau that halts team’s progress towards a more effective flow-based approach.
CD Works Better!
In one of my more successful consulting projects I worked with a moderately large team in a very big organisation, that had nominally adopted SAFe. There were several hundred people in the team that I was working with.
Inevitably, I guided them using Continuous Delivery principles. Starting points were “work so that your SW is always releasable” and “optimise for speed of feedback”. This team outperformed, based on internal company metrics, every other team in the org and now acts as an example and coach for others in the org.
It is Hard to Change
I don’t think SAFe is evil, I can imagine some circumstances, with the right combination of people, where it would work. The trouble is that you can say that about anything, even waterfall sometimes works by accident, if you have people in-place that can navigate it.
I think that SAFe is misguided.
It is incredibly difficult to make changes in big orgs, but I don’t see any evidence that SAFe helps on that journey.
Having said all of that, my experience is limited, please do let me know in the comments where I am wrong in this?
This year I started a YouTube channel in which, every week, I discuss ideas related to Continuous Delivery. I have been very pleased with its success.
As part of that, but also because of working from home more as a result of the COVID pandemic, I began to take a more active part in Twitter. The combination of these things is that I now feel much more strongly, than I did before, part of a community. There are a large group of us that regularly communicate and discuss ideas on Twitter and sometimes in the comments on my YouTube channel.
A regular contributor, and digital friend, on both, Jim Humelsine, commented on my latest YouTube video which discusses the topics of Continuous Delivery and Continuous Deployment. Two closely related ideas that are subtly different, and that are the topic of this week’s episode on my channel.
I thought that it was a really good question and that it may help to clarify my answer to it here as well as in the comments section of YouTube. So this post is about definitions and subtle differences in what we mean in the language that surrounds the practice of Continuous Delivery and DevOps.
Jim’s question
“Can you please restate definitions for Release, Deploy and Delivery? I’m still a bit confused among them, especially the distinction between Deploy and Delivery.”
My answer
It is confusing and my wife, Kate, pointed out to me recently that I am not completely consistent in how I use the words. I use the words in the following way:
Deploy – The technical act of copying some new software to a host environment and getting it up-and-running and so ready for use. In context with ‘Continuous’ as in ‘Continuous Deployment’ I use it to mean ‘automating the decision to release’ – If your deployment pipeline passes, you push the change to production with no further actions.
Release – Making a new feature available for a user to use. (Note: we can deploy changes, that aren’t yet ready for use by a user, when we make them available to a user, with or without a new deployment, we release them – I plan to do a video on strategies for this).
Delivery – In context with ‘Continuous’ I generally mean this in a broader context. for me ‘Continuous Delivery’ makes most sense as used in the context of the Principles listed in the Agile Manifesto – ‘Our highest priority is the early and continuous delivery of valuable software to our users’. So it is about a flow-based (continuous) approach to delivering value. That means that the practices need to achieve CD are the practices needed to maintain that flow of ideas – so it touches on all of SW dev. I know that this is an unusually broad interpretation, but it is the one that makes the most sense to me, and the one that I find helps me to understand what to do if I am stuck trying to help a team to deliver.
There is, as far as I know, one place where my language is regularly a bit inconsistent, at least one place that Kate has told me about. I tend to talk about working towards “Repeatable, Reliable Releases”, if I were willing to drop the alliteration and speak more accurately what I really mean is “Repeatable, Reliable Deployments”.
I hope that this helps a bit?
If you are interested in taking a look at my YouTube channel you can find it here.
If you would like to join a group of opinionated people over on Twitter you can see my stuff here.
First, I’d like to say welcome. You’ve chosen a great industry and profession in which to pursue a career. We software developers are changing the world. We are changing the world with a unique form of creativity, and that is something to keep with you while continuing to challenge yourself throughout your career. So welcome. I think you’ve made a fantastic choice.
Who’s Advice?
I recently asked my Twitter and LinkedIn followers what their advice for junior developers might be, and I have gathered responses from a wide range of professionals. From those that are only a few steps ahead of you, to others at the very top of the industry. Some of these people are likely to be the people that are your leaders and the people that make hiring decisions.
“Everyone is ‘Junior'”
The most common response, in one way or another, was to remember that everybody is a junior at something. Everybody, including those professionals at the top of the industry.
All software developers should be learning something new, all of the time. I am considered an expert in a number of development practices, yet I have recently picked up a project in which I am learning to programme in Angular JS. Something I have never done before.
This constant learning is part of our discipline and it differentiates us from many other industries. It is true of other industries too, but I think that it is more true of ours. This, in many ways, is the real essence of what we do. So this is always true. Keep on learning!
Not Knowing the Answer
This leads to my first, and potentially the most important piece of advice. It’s OK to say ‘I don’t know’. Nobody knows everything. Software development is a vast and extensive thing. There are so many technologies and disciplines that nobody in the world is an expert at everything.
More than that though, “not knowing” is fundamental to what we do. We are always creating something new, and exploring ideas that are new to us, and sometimes to the world. It takes a little while to learn this, but not knowing isn’t something to be embarrassed about, in fact, you will spend your career not knowing.
I like to apply scientific-style thinking to software development, after all, if software really is about “not knowing” then we need to learn to be really good at learning, and humanity has no better approach to learning than science.
Failure is ALWAYS an Option!
One of the key lessons in science is to proceed in a series of experiments, validating our guess as we go. This means that you shouldn’t be afraid of failure. Failure is where we learn our most valuable lessons. Focus on what is in front of you right now and apply effective learning techniques to solve those problems.
Try not to become overwhelmed by the complexity or the size of a task. Take it one step at a time. If we want to minimize the danger of making a mistake, then we want to be able to make those mistakes on a small scale. Dividing our work up into small, controlled, units of progress allows us to see whether it is worth taking that next step or not. Does this change move us forwards, or is it a step backwards?
Choose Your Own Boss
A good mentor can guide your path to learning, so look out for somebody who can fill that role. I put it like this, choose your own boss. This won’t necessarily be your boss by hierarchy, but somebody you can look up to, learn from, and call on for help.
If you are in the process of interviewing for jobs, try to recognise where you might be best supported as a new developer. Make sure you show up to interviews with your own questions on that topic. A good team and organisation will have no problem with you questioning the support system that they provide. Whether you are currently in a position of work or making applications, take yourself and your career seriously. Evaluate your best routes for success and take them.
Learn by Playing
Not only should you think about your professional progression, but take time to recognise what you really enjoy about writing code and developing software. Play with software. Do things for yourself.
I started my fascination with software by creating games and then went on to develop other silly things for my own entertainment. I actually have a video on YouTube about the dumbest things I’ve ever programmed (Watch here: https://bit.ly/Top5DumbCode).
They might have been dumb, but they provided significant entertainment to myself and coworkers around me. There’s no better avenue for success than enjoying what you do.
Focus on the Fundamentals
The fundamentals of software development do not change. Which means they are more important than any tool, language or framework. Those fundamentals are where the real skill of a developer lies, so focus on the fundamentals.
When you are starting out you will inevitably have a strong focus on learning the tools of our trade, but be careful. The tools that really matter aren’t all obvious. Sure you need to know the language, dev environments and frameworks that you are using. However, over the course of your career, these will come and go. The real tools are more foundational.
It is unfortunate that recruitment doesn’t always work this way. Recruitment often works by having checklists of tools and technologies, rather than recognising the problem-solving techniques that are the real heart of our industry. This is particularly true when recruiting junior developers. As it’s hard to demonstrate your capability, let alone potential, so many organizations resort to these simple check-lists.
This is, of course, a poor way to go about recruitment, but it is often the approach taken by many firms. Remember, that this is not what makes you a great software developer. A long list of tech in your Resume or CV doesn’t make you good at software development.
Learn the Skills to Compartmentalise Problems
My final piece of advice goes back to the idea that it is ok to say, ‘I don’t know’. The human brain is limited by capacity, there’s only so much stuff we can genuinely understand, and these days, we build software systems far beyond that capacity. We need ways to manage that complexity.
As developers we need to become experts at the techniques of compartmentalising problems and our solutions to them. Take that idea seriously!
Compartmentalise and create ‘modular systems’ to divide up any problem into pieces that are more manageable. Related ideas in you code should be close together, this is called Cohesion.
Each piece of your code should be focussed on achieving one thing. Use separation of concerns as a tool to help you to create better designs with better Modularity & Cohesion. Value the readability of the code that you create, and do what you can to make your code easy to work on. Seek out examples of good code, and maybe bad. Be opinionated about what makes good code good!
One of my favourite descriptions of “Good Design” comes from Kent Beck:
“Good design is moving things that are related closer together and things that are unrelated further apart”
Enjoy the Journey
I am attempting to do a small part in helping with your learning on my YouTube Channel…
and My MailList, where I regularly publish useful guides on ideas and practices that seem important to me…
I hope that these pieces of advice can be helpful to you. Take time to appreciate the journey. Look to where you can best succeed and work on a career that can leave you feeling truly fulfilled. And I shall say it again. Welcome. You’ve made a great choice.
For more top tips and advice for junior developers watch my YouTube video here!
When Jez and I wrote our book, we knew that we were describing a powerful approach. We were very nervous of claiming a “Methodology” though. Instead we saw the Continuous Delivery book as describing, in some detail, an approach to Build, Test and Deployment Automation and hinting at something broader in-scope.
I am less reticent these days. I have seen the philosophy of Continuous Delivery transform organisations. I have been personally involved in helping many firms make this shift. I now make no bones, CD is a holistic approach that extends a long way beyond merely Build, Test and Deployment Automation.
Working so that you are in a position to deliver value into the hands of your users and customers continuously is a radical change, but it is now measurably, demonstrably the most effective way that we humans currently know how to create great software.
The impact on teams and organisations is profound. Continuous Delivery as a discipline is not just about the technicalities either in terms of practice or impact.
From my own experience, but also backed-up by over 10 years of robust research, studies and the experience of software developers around the world, I now know that Continuous Delivery has the following benefits:
We can create better software faster, with no trade-offs between those two ideas.
We can reduce defect counts by multiple orders of magnitude.
We can spend a significantly greater proportion of our time on new ideas and less on unplanned tasks.
We can innovate more quickly and steer our businesses towards greater financial success.
We can solve harder problems.
We can have a better work/life balance while doing all of these things.
We can work with less stress, and more creativity.
We can be more compliant and safer in regulated and safety-critical industries.
We can revolutionise the organisations in which we work.
We can do all of these things whatever the nature of the software.
I now believe that this engineering-led approach is not only generally applicable, but is the best way to create any software.
I asked some people that I know, who have personal experience of employing Continuous Delivery in businesses of all sizes, to comment on this impact:
“Continuous Delivery helps us focus effort on things that bring value to our customers, instead of wasting time on repeatable and automate-able tasks in configuration, testing and deployment. It enables us to move fast with confidence, frequently applying small changes and keeping our product quality high and deployment risk low. MindMup.com is a product of a two-person team, serving millions of users across the world. The two of us do everything from user research through development, testing and operations tasks, to customer support. There’s no way we’d be able to achieve any kind of delivery speed if our releases required a lot of work or caused customer support requests. Software quality and stability are essential so we can focus on adding value instead of fixing bugs. Investing in continuous delivery practices pays off big because it delegates repeatable tasks to machines and frees up our time to work on things that actually require human insight, allowing us to successfully compete with several orders of magnitude larger organisations.”
The automation that Gojko describes is a central practice in CD. I like that he uses the word “Investing” though. I speak to many teams starting out who claim that they don’t have time to automate. This is a bit like saying that you are going to walk from London to Edinburgh because you don’t have the time to put petrol in your car.
“Working with large enterprises, I’ve seen that the technical agility Continuous Delivery supports can be leveraged for greater business agility. With that in mind, it was easy to believe Dr. Forsgren’s research showing better business performance from teams adopting DevOps. I put my money where my mouth is, so to speak, and invested in companies who convince me that they’re dedicated to DevOps and Continuous Delivery. My only regret to date is not investing more.”
Since the publication of my book, I have grown to believe that the reason that CD works is quite profound. I believe that CD is founded on the application of scientific principles to solving problems in software. We make evidence-based decisions, use falsification, form hypotheses that we test in the form of (often automated) experiments. We proceed in small steps, validating our learning and understanding as we progress. We control the variables with techniques like Infrastructure as Code.
For me CD is a genuine “Engineering Discipline for Software“. I too find Dr Fosgren’s work (described in the excellent “Accelerate” book) compelling. We have a measuring stick (Stability & Throughput) and correlative model that can guide our efforts to learn to create “Better Software Faster“.
“Working on a software product with long upgrade cycles, my team felt caught between sales demanding features immediately and customers who couldn’t immediately adopt and didn’t want frequent releases. We rearchitected to enable more of a Continuous Delivery approach and zero downtime updates to just one area of the product that was a magnet for these sales requests. That investment gave us the agility we needed where we needed it. The developer/sales relationship improved as did the business.”
Eric points out that this is NOT just a technical impact. CD has a revolutionary impact on the way in which the business that employ it can operate. Organisations that practise Continuous Delivery “have a 50% higher market cap growth over 3 years“
“I would love to say that it made NS better, faster, cheaper, and happier – although many believe this we still can’t really prove that with data! I can say however that our CD efforts in 2016/17, and the Agile and DevOps transformation that followed, has led to greater ownership by the teams, to fundamental discussions about organization and governance of software development, and to improved understanding and alignment between business and IT. And of course, in the meanwhile, teams have automated everything they could, supported by a fine tool suite and plenty of coaches.”
Huub van der Wouden Dutch National Railways
The adoption of Continuous Delivery is not easy. Because of its holistic nature the changes sometimes proceed slowly, but even then the impact is significant. The data from CD teams is interesting in terms of cultural performance as well as technical. Teams that practise CD claim better work/life balance, lower stress, and a greater sense of ownership.
“At Siemens Healthineers, we have a growing number of teams adopting Continuous Delivery in the heavily regulated medical device industry. Currently, we have 20+ teams on the journey to Continuous Delivery. Different teams adopt various Continuous Delivery ways of working at different rates. Some teams are further ahead than others. What we have seen over the years is a growing appetite for Continuous Delivery, which is set to continue in future. Teams making breakthroughs in e.g. testing, deployment etc. never look back but rather want to achieve more!”
Vladyslav Ukis Siemens Healthcare
Vlad describes another, growing, impact of CD. It is almost impossible to imagine the creation of a Deployment Pipeline without getting a perfect audit-trail of production changes as a side-effect. This, and other properties, make CD the perfect approach for regulated and safety-critical industries. I wrote about this in this blog post on “Continuous Compliance“.
“On the cost side, the software delivery has to be optimized for small chunks, in order to support the revenue side of the story. This requires the delivery organization to be set up in such a way that development teams can make releases independently. This holds true irrespective of the number of teams. That is, the cost of running the organization (overhead) does not significantly increase when the number of teams increases. Additionally, the teams can be trained to work in a way that allows them to accelerate over time. This reduces the cost per small batch delivery over time.
On the capital allocation side, the software delivery in small chunks has another business advantage. If an organization has a software delivery capability with small chunks, it enables investments in software products to be placed with a stop option, which can be exercised at any time. This way, you can invest a little, see whether the results are promising, invest a little more if they are, reduce the investment if they are not, and keep going this way. It is an efficient way to allocate the capital bit by bit taking small risks and evaluating results along the way. The stop option allows the capital to be invested with an in-built risk reduction strategy.
For the reasons above, I would not want to invest in software products that are not built using Continuous Delivery!”
Vladyslav Ukis Siemens Healthcare
Working in smaller steps is natural in CD. It gives faster, clearer feedback of each change and is promoted by an efficient Deployment Pipeline. It is is also extremely valuable to businesses. It allows them to try new ideas at lower cost, to be more reactive to customer or market demand. It also allows them to take the safety of the systems that they create more seriously too. If a change is small and simple, it is also lower risk, easier to diagnose if something goes wrong and easier to remove if necessary.
“CI is a communication tool. It alerts people working on a system that they need to talk to other people to resolve a potential conflict between the work they are doing separately. Or at least, appeared to be doing separately until CI detected the work wasn’t as separable as they thought. That’s why integrating “at least once a day” is not a useful definition any more. Do you want to waste a day’s work before dealing with any conflicts? CI should provide that alert as fast as possible.”
“Integration should happen so frequently that when a conflict occurs, it’s quicker for the people involved to have a discussion, discard some of the changes and write them again than it is to merge their changes.”
“Continuous Deployment changes the way you can think about architecture. It gives you more choices about where data and logic can be placed. When you can safely/rapidly/automatically redeploy any components of an application at any time, you can choose to place data or logic in those components rather than in separate services or databases.”
“CI/CD pipelines are not a “dev” environment. They are critical to the functioning of the production system, because they are the way fixes get deployed into production when there is an incident.”
Nat points out the profound impact that thinking about fast-feedback and test-ability has on the software that we create. In general “quality” in code and systems has been an issue of experience and talent. Continuous Integration, and its big brother Continuous Delivery, apply a separate pressure for higher quality.
If you can’t release into production if a single test fails (a recommended CD practice) then keeping the tests passing is central to the approach. To keep the tests passing you need “repeatable reliable” tests. If you want your tests to be deterministic, then you need to make your code testable. The properties of testable code are the properties that we value as the hallmarks of high-quality software.
Of course this still depends on the talent and ingenuity of development teams, but it applies a pressure to do the right things that otherwise only exists as a matter of personal discipline. CD is a GREAT tool to drive a better focus on higher-quality work and provides a mechanism to give clearer feedback to developers on the quality of their work. (I described this idea, in part, here)
“I highly recommend this book <Continuous Delivery>. Working at LMAX where we put into practice many of these things fundamentally changed the way I think about software development”
“I’ve seen that organisations that have adopted CD spend significantly less time on releases. Higher levels of automation means much less (if not zero) time spent by developers and operations team members on evenings and weekends. This is beneficial in a number of ways: less overtime; less time spent on releases means more time to develop features; less human interaction means a lower risk of human-introduced errors; and a happier, more productive team environment (which is great for recruitment and retention).”
Trisha Gee, JetBrains
Trish describes how the technical practices of CD reinforce the desirable human outcomes for the people working on these teams. Less stress, better work/life balance and generally a better, more creative, higher-quality work environment.
“Our CI/CD environment is consistently humbling our development team with failing tests that were not expected. Most of these failures would have silently made their way to production unnoticed.”
“Our CI/CD environment is able to provide fast accurate feedback because our developers are empowered to write tests that stand up to a rigorous cost benefit analysis rather than simply adding tests to meet some arbitrary code coverage metric”
Judd Gaddie (TransFICC)
Judd’s team operates a sophisticated CD approach delivering very high-class software. CD is an engineering discipline in that if you follow the practices your will certainly get a higher-quality result. Measured in terms of speed and quality.
“We are able to make large, cross cutting changes to our system with high-levels of confidence due to the quality of our CD pipeline. We were able to completely re-write the architecture of our system and know it worked from our pipeline (we didn’t have to change any acceptance tests either!). Some things that spring to mind but are not necessarily CD related…
The first thing we built when we started the company was our CD pipeline and a feedback screen. Whilst it meant we sent slowly at the beginning it has meant we have always had a strong testing pipeline and allowed us to focus on automating everything and provided an easy way of showing whether our software works or not. It has also provided credibility to the company in a way of showing we know what we are doing Zero time spent “preparing” a release as trunk is always releasable”
Tom McKee (TransFICC)
Tom takes us back to the start with the idea of investing in our approach and our work. Work done to make us more efficient is not waste, it helps us to eliminate waste. For Continuous Delivery teams there is no trade-off between speed and quality. In fact investing so that you can go quickly naturally leads to working in smaller steps and promotes higher-quality outcomes.
I believe that Continuous Delivery represents the “state of the art” for software development. I also believe that this approach is a genuine “engineering discipline” for software development.
Continuous Delivery does what engineering does in other fields, it amplifies our craft and creativity and allows us to create machines and systems with greater speed, quality and efficiency. There is no better way, that we know of, to create high quality software efficiently.
So, ten years after my book was first published, I am very proud of the impact of these ideas, and in my part in popularising them, but there is still a lot more work to do, so I am looking forward to the next 10.
My book, “Continuous Delivery” was launched on 10th August 2010, so in a few weeks time it will be the 10th anniversary of its publication. Jez and I spent 4 years writing the book, and several years before that doing the work that informed that writing. Continuous Delivery has been a feature of my life for a long while now.
I very clearly recall the sense of pride when our book was published, nevertheless neither of us thought that it would have the impact that it has and that the ideas would become so widely recognised as the state of the art in software development approach. Continuous Delivery is now the approach behind the work of many of the biggest and most successful software-driven organisations on the planet.
Originally we had a few celebratory things planned for this 10th anniversary year. Jez and I spoke together for the first time at the DeliveryConf in Seattle, at the start of the year (you can watch it here: https://youtu.be/FVEWdatM8Uk). Then a global pandemic reminded us of the limits of our planning.
The Importance of CD
I have spent the last few years working as an independent software consultant, advising clients on how to improve their software engineering practices, with Continuous Delivery at the heart of those improvements. I have become more convinced, rather than less, that the ideas in Continuous Delivery are important, and bigger than I thought when we wrote the book.
I believe that the reasons why CD works is that it is rooted in some deep, important ideas. It is primarily focussed on learning efficiently. CD works by creating fast, efficient, high-quality feedback loops that operate from the few seconds of feedback from a TDD test run, to the feedback generated by creating a releasable thing multiple times per day. It also facilitates that most important feedback loop of all, from customer to producer. Allowing organisations to experiment with their products and hone them to better meet the needs of customers and so create great products.
When we came up with the ideas and practices of CD it was done as an exercise in empirical learning and pragmatic discovery. We did none of this based on theory, all was based on practical experience in real software projects. Since then, through my experience of helping people to understand and adopt these practices in all sorts of organisations, for all kinds of software, I now recognise some deeper explanations for why CD works.
CD As an “Engineering Discipline”
I believe that CD represents a genuine “engineering” approach to solving problems in software. By that what I mean is that we are applying some important scientific principles to software. Despite us thinking of our discipline as technical, it has been surprisingly un-scientific in approach. Most software dev proceeds as a series of guesses, we guess what users want, we guess at a design, we guess, usually based on a convincing expert or colleague which tech we will use, we guess if there are bugs in it on release. I believe that CD, when taken seriously and practiced as a core, organising, discipline for software development, rather than interpreted as meaning only “deployment automation”, helps us to eliminate much of this guesswork. Instead we create hypotheses, try them out as mini-experiments, we accurately measure the results and we work to control the variables so that we can distinguish signal from noise.This is “engineering” and the results when we apply it are astonishing and dramatic, as shown by Jez’s work with Nicole Fosgren.
My CD Mission
So ten years later, I feel like I am on something of a mission. Of course I am delighted at the success of our book and the impact that it has had on teams all around the world. I am also personally grateful for the impact that it has had on my career. I am now seen as an expert in this field and have travelled the world helping people and teams as a direct result of that literary success. However, my mission is not done.
I believe that CD matters because Software matters and CD is THE BEST WAY TO CREATE SOFTWARE with speed, efficiency and quality.
So thank you for your support over the years. I hope that you have enjoyed my book, and my other stuff.
I have some other things in the pipeline to, hopefully, help me with my mission which is to help teams and individuals improve their skills, techniques, and perhaps most important of all, engineering approach to software development.
A New Book?
I am working on another book, in which I explore in some depth this idea of what “Engineering” should mean for the discipline of software development. What form would a genuine “engineering discipline for software” take? I am not good at predicting when I will finish books, but this one is progressing quite well so I am hoping that it will be published next year.
CD Online
My YouTube Channel
I had been very busy with my consultancy, and so in some sense the pandemic gave me the impetus, and the time, to do something that I had been thinking about for a long time.
I have begun a series of videos, published weekly (every Wednesday evening, UK time) on YouTube, in which I explore different aspects of, and different ideas that are prompted by, Continuous Delivery and its practice.
My “Continuous Delivery Channel” covers my thoughts and experiences on Continuous Delivery, DevOps, TDD, BDD and Software Development as an Engineering discipline. It is quite wide-ranging talking about the technical, cultural and organisational practices and impact of Continuous Delivery.
I have been very pleased with the growth of the channel so far, and naturally hope that it will continue to be interesting, and useful, to people.
Continuous Delivery Training Courses
I am also in the process of getting most of my training courses set up on-line. But that takes a bit longer, so I’ll be saying more about these later in the summer. My on-line training programme will include:
"Getting Started With Continuous Delivery"
"Anatomy of a Deployment Pipeline"
"TDD - Design Through Testing"
"ATDD - Stories to Executable Specifications"
"Leading Continuous Delivery"
I have plans for many more, but this is already a lot of work 🙂
My goal is to share the best ideas about how to build better software, faster. So if you have a particular interest that we can explore in one of my next YouTube videos, or if you have a particular training need, please let me know.
CD Mail-List
Finally I have set up a mail-list via which I will share thoughts and keep people informed of any news. To celebrate the 10th anniversary of my book, and to say thank you to subscribers to my mail list, I am running a competition, I am giving away a signed, first-edition, copy of “Continuous Delivery”. Everyone on the email list is eligible for the draw, so if you haven’t already, please sign-up.